MAPO: Advancing Multilingual Reasoning through Multilingual Alignment-as-Preference Optimization
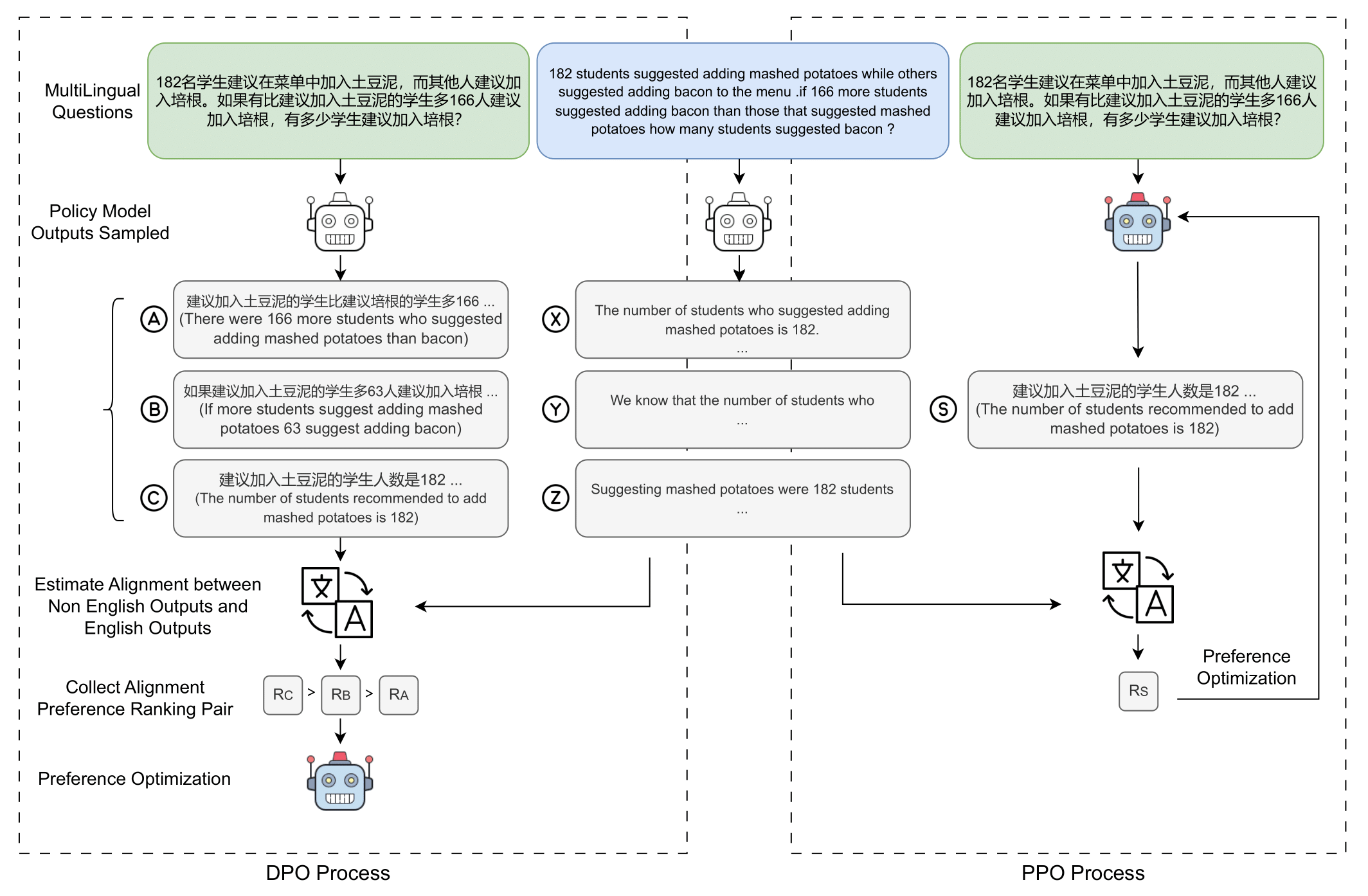
Though reasoning abilities are considered language-agnostic, existing LLMs exhibit inconsistent reasoning abilities across different languages, e.g., reasoning in the dominant language like English is superior to other languages due to the imbalance of multilingual training data. To enhance reasoning abilities in non-dominant languages, we propose a Multilingual-Alignment-as-Preference Optimization framework (MAPO), aiming to align the reasoning processes in other languages with the dominant language. Specifically, we harness an off-the-shelf translation model for the consistency between answers in non-dominant and dominant languages, which we adopt as the preference for optimization, e.g., Direct Preference Optimization (DPO) or Proximal Policy Optimization (PPO). Experiments show that MAPO stably achieves significant improvements in the multilingual reasoning of various models on all three benchmarks (MSVAMP +16.2%, MGSM +6.1%, and MNumGLUESub +13.3%), with improved reasoning consistency across languages.
PDF Abstract

