MA-LMM: Memory-Augmented Large Multimodal Model for Long-Term Video Understanding
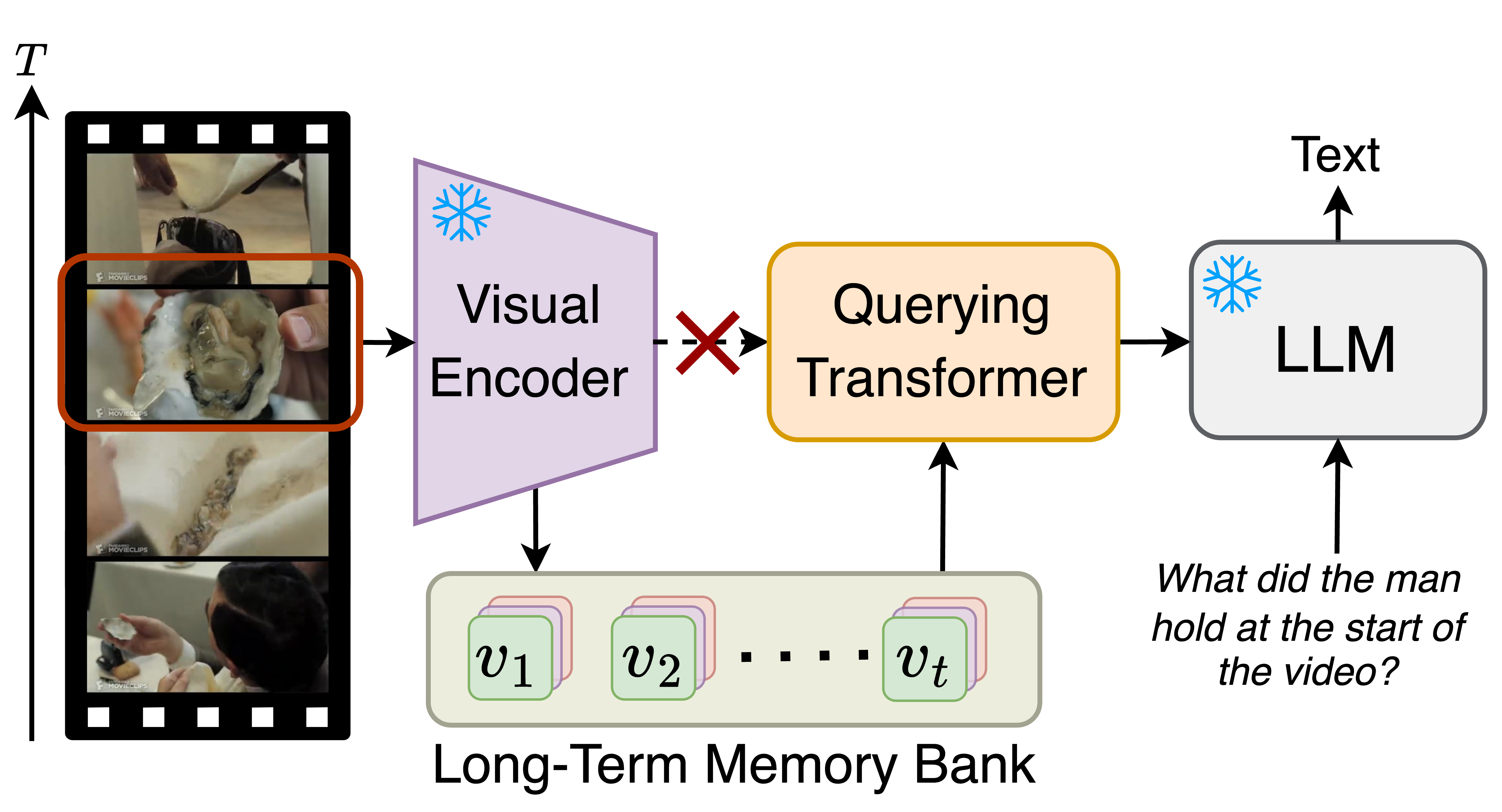
With the success of large language models (LLMs), integrating the vision model into LLMs to build vision-language foundation models has gained much more interest recently. However, existing LLM-based large multimodal models (e.g., Video-LLaMA, VideoChat) can only take in a limited number of frames for short video understanding. In this study, we mainly focus on designing an efficient and effective model for long-term video understanding. Instead of trying to process more frames simultaneously like most existing work, we propose to process videos in an online manner and store past video information in a memory bank. This allows our model to reference historical video content for long-term analysis without exceeding LLMs' context length constraints or GPU memory limits. Our memory bank can be seamlessly integrated into current multimodal LLMs in an off-the-shelf manner. We conduct extensive experiments on various video understanding tasks, such as long-video understanding, video question answering, and video captioning, and our model can achieve state-of-the-art performances across multiple datasets. Code available at https://boheumd.github.io/MA-LMM/.
PDF Abstract



 MSR-VTT
MSR-VTT
 MSVD
MSVD
 YouCook2
YouCook2
 Breakfast
Breakfast
 ActivityNet-QA
ActivityNet-QA

