Low Light Video Enhancement using Synthetic Data Produced with an Intermediate Domain Mapping
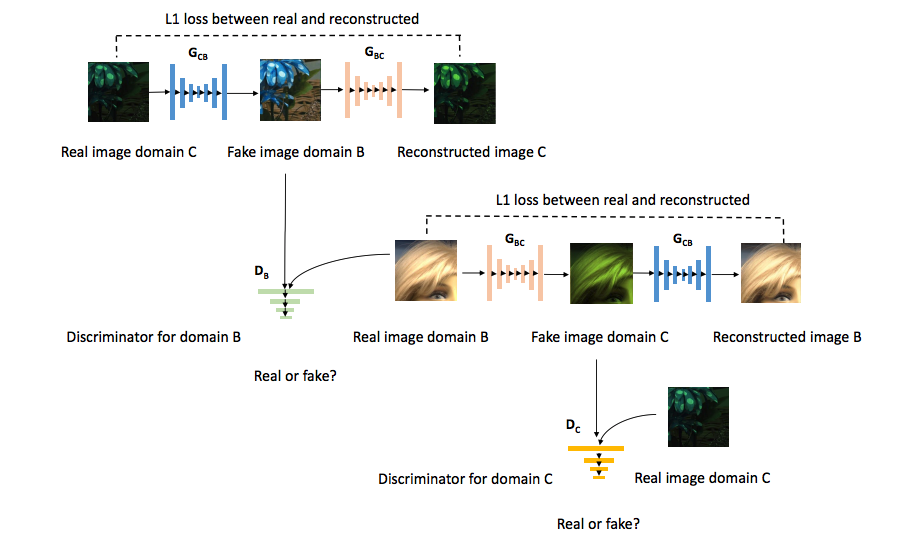
Advances in low-light video RAW-to-RGB translation are opening up the possibility of fast low-light imaging on commodity devices (e.g. smartphone cameras) without the need for a tripod. However, it is challenging to collect the required paired short-long exposure frames to learn a supervised mapping. Current approaches require a specialised rig or the use of static videos with no subject or object motion, resulting in datasets that are limited in size, diversity, and motion. We address the data collection bottleneck for low-light video RAW-to-RGB by proposing a data synthesis mechanism, dubbed SIDGAN, that can generate abundant dynamic video training pairs. SIDGAN maps videos found 'in the wild' (e.g. internet videos) into a low-light (short, long exposure) domain. By generating dynamic video data synthetically, we enable a recently proposed state-of-the-art RAW-to-RGB model to attain higher image quality (improved colour, reduced artifacts) and improved temporal consistency, compared to the same model trained with only static real video data.
PDF Abstract ECCV 2020 PDF ECCV 2020 Abstract
 Vimeo90K
Vimeo90K
 SID
SID
