Look\&Listen: Multi-Modal Correlation Learning for Active Speaker Detection and Speech Enhancement
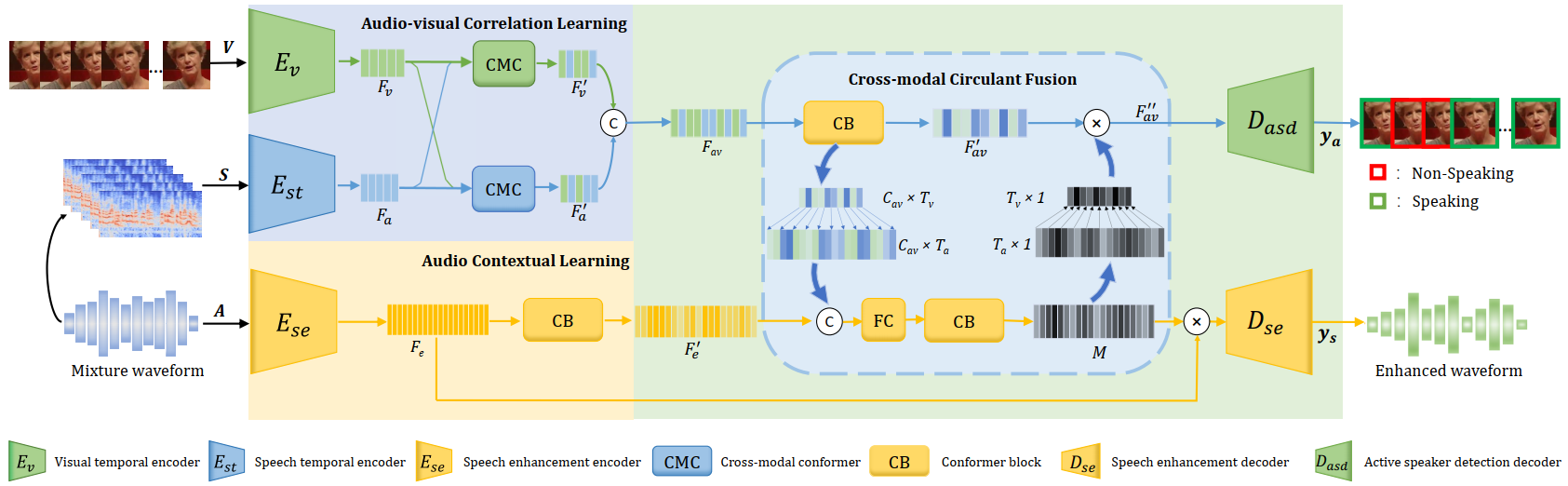
Active speaker detection and speech enhancement have become two increasingly attractive topics in audio-visual scenario understanding. According to their respective characteristics, the scheme of independently designed architecture has been widely used in correspondence to each single task. This may lead to the representation learned by the model being task-specific, and inevitably result in the lack of generalization ability of the feature based on multi-modal modeling. More recent studies have shown that establishing cross-modal relationship between auditory and visual stream is a promising solution for the challenge of audio-visual multi-task learning. Therefore, as a motivation to bridge the multi-modal associations in audio-visual tasks, a unified framework is proposed to achieve target speaker detection and speech enhancement with joint learning of audio-visual modeling in this study.
PDF Abstract


 VoxCeleb2
VoxCeleb2
