Look Before You Leap: Bridging Model-Free and Model-Based Reinforcement Learning for Planned-Ahead Vision-and-Language Navigation
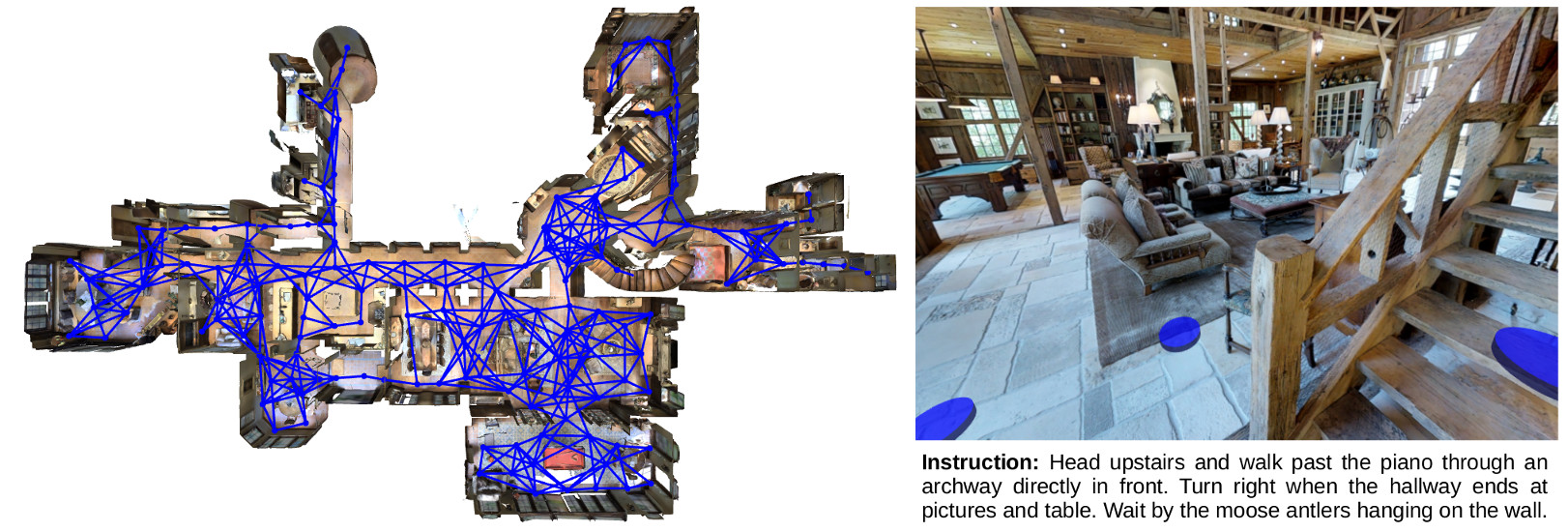
Existing research studies on vision and language grounding for robot navigation focus on improving model-free deep reinforcement learning (DRL) models in synthetic environments. However, model-free DRL models do not consider the dynamics in the real-world environments, and they often fail to generalize to new scenes. In this paper, we take a radical approach to bridge the gap between synthetic studies and real-world practices---We propose a novel, planned-ahead hybrid reinforcement learning model that combines model-free and model-based reinforcement learning to solve a real-world vision-language navigation task. Our look-ahead module tightly integrates a look-ahead policy model with an environment model that predicts the next state and the reward. Experimental results suggest that our proposed method significantly outperforms the baselines and achieves the best on the real-world Room-to-Room dataset. Moreover, our scalable method is more generalizable when transferring to unseen environments.
PDF Abstract ECCV 2018 PDF ECCV 2018 Abstract


 Matterport3D
Matterport3D
 R2R
R2R
