Location-Sensitive Visual Recognition with Cross-IOU Loss
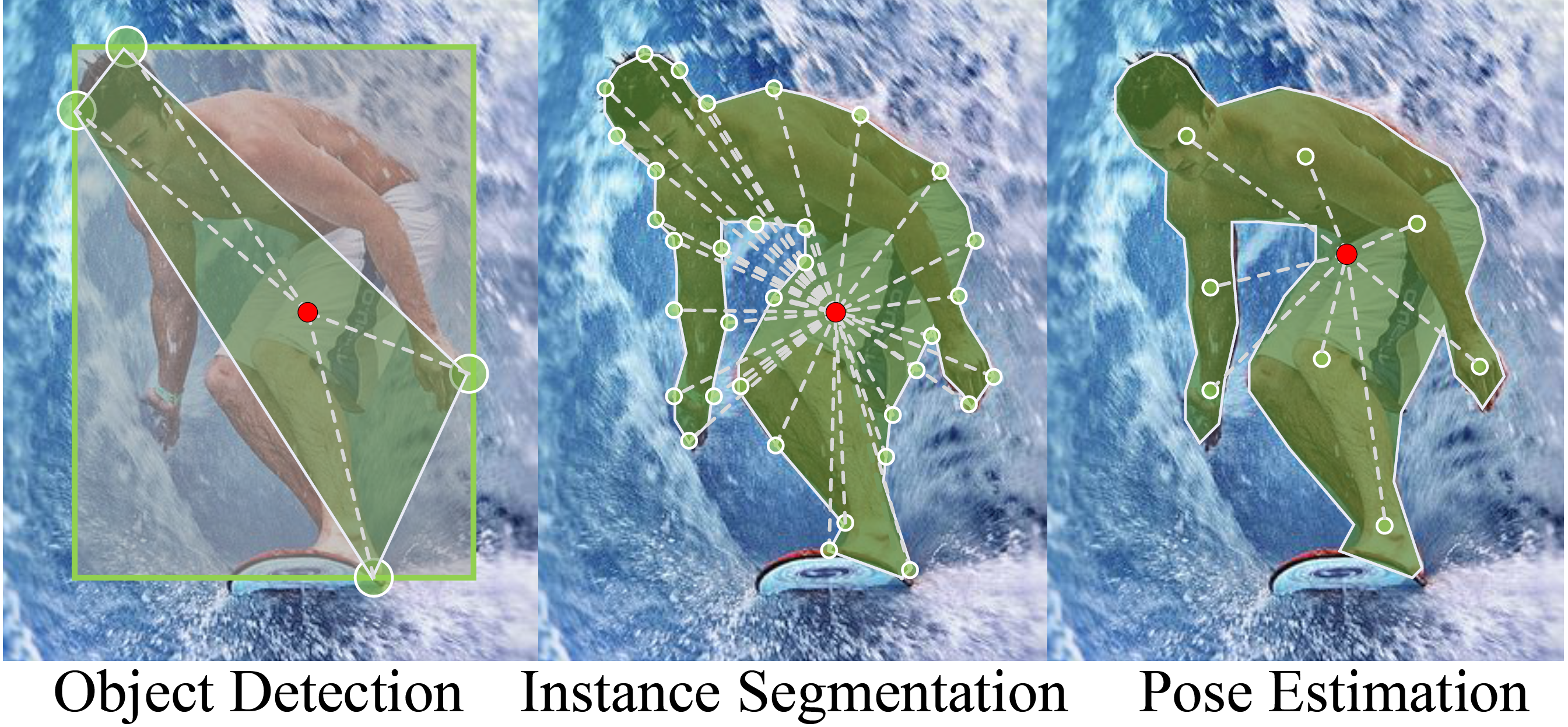
Object detection, instance segmentation, and pose estimation are popular visual recognition tasks which require localizing the object by internal or boundary landmarks. This paper summarizes these tasks as location-sensitive visual recognition and proposes a unified solution named location-sensitive network (LSNet). Based on a deep neural network as the backbone, LSNet predicts an anchor point and a set of landmarks which together define the shape of the target object. The key to optimizing the LSNet lies in the ability of fitting various scales, for which we design a novel loss function named cross-IOU loss that computes the cross-IOU of each anchor point-landmark pair to approximate the global IOU between the prediction and ground-truth. The flexibly located and accurately predicted landmarks also enable LSNet to incorporate richer contextual information for visual recognition. Evaluated on the MS-COCO dataset, LSNet set the new state-of-the-art accuracy for anchor-free object detection (a 53.5% box AP) and instance segmentation (a 40.2% mask AP), and shows promising performance in detecting multi-scale human poses. Code is available at https://github.com/Duankaiwen/LSNet
PDF AbstractCode






 ImageNet
ImageNet
 MS COCO
MS COCO

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Object Detection | COCO test-dev | LSNet (Res2Net-101+ DCN, multi-scale) | box mAP | 53.5 | # 56 | |
| AP50 | 71.1 | # 27 | ||||
| AP75 | 59.2 | # 19 | ||||
| APS | 35.2 | # 18 | ||||
| APM | 56.4 | # 17 | ||||
| APL | 65.8 | # 21 | ||||
| Hardware Burden | None | # 1 | ||||
| Operations per network pass | None | # 1 |
