Local Learning with Neuron Groups
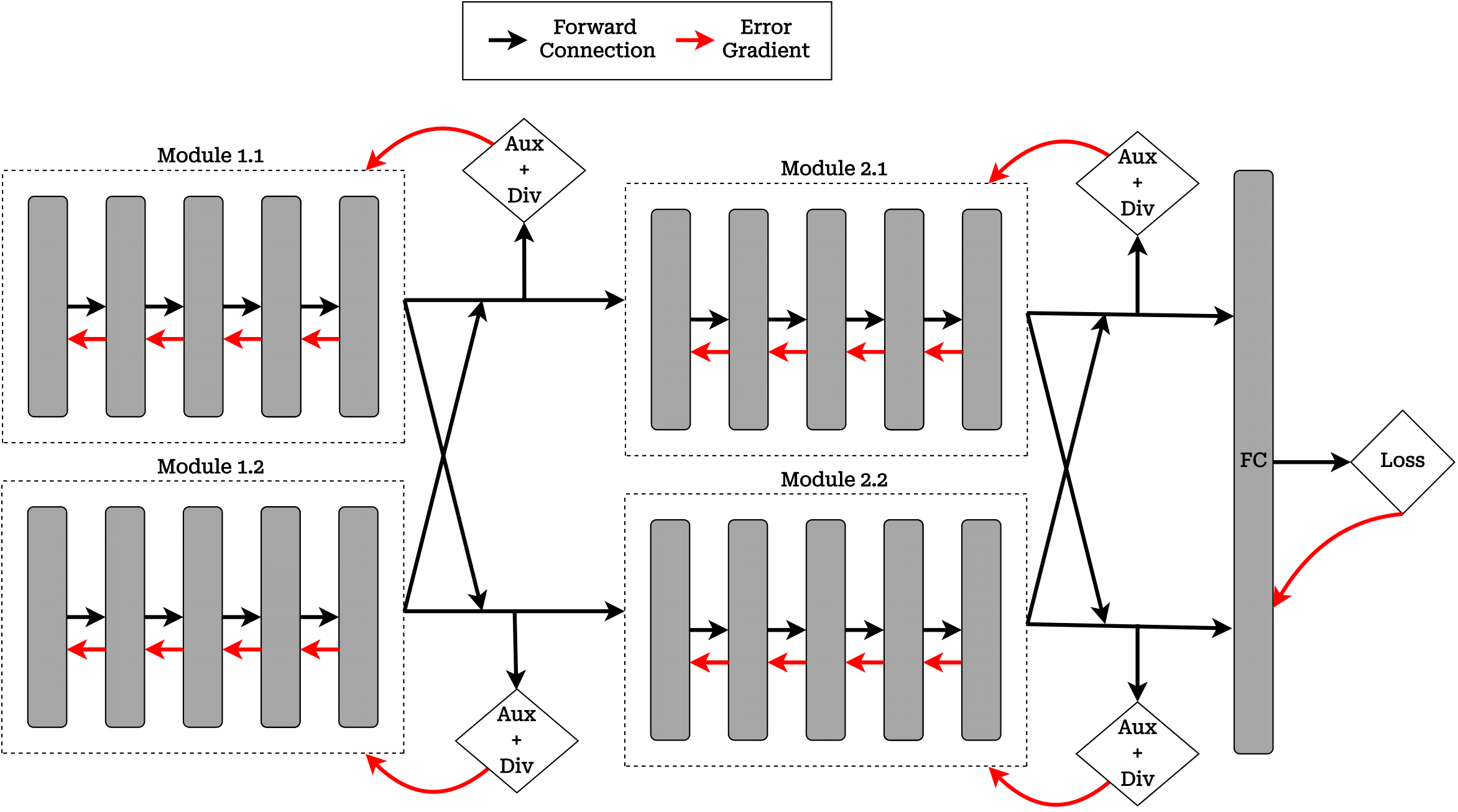
Traditional deep network training methods optimize a monolithic objective function jointly for all the components. This can lead to various inefficiencies in terms of potential parallelization. Local learning is an approach to model-parallelism that removes the standard end-to-end learning setup and utilizes local objective functions to permit parallel learning amongst model components in a deep network. Recent works have demonstrated that variants of local learning can lead to efficient training of modern deep networks. However, in terms of how much computation can be distributed, these approaches are typically limited by the number of layers in a network. In this work we propose to study how local learning can be applied at the level of splitting layers or modules into sub-components, adding a notion of width-wise modularity to the existing depth-wise modularity associated with local learning. We investigate local-learning penalties that permit such models to be trained efficiently. Our experiments on the CIFAR-10, CIFAR-100, and Imagenet32 datasets demonstrate that introducing width-level modularity can lead to computational advantages over existing methods based on local learning and opens new opportunities for improved model-parallel distributed training. Code is available at: https://github.com/adeetyapatel12/GN-DGL.
PDF Abstract
 ImageNet-32
ImageNet-32
