LLM-QBench: A Benchmark Towards the Best Practice for Post-training Quantization of Large Language Models
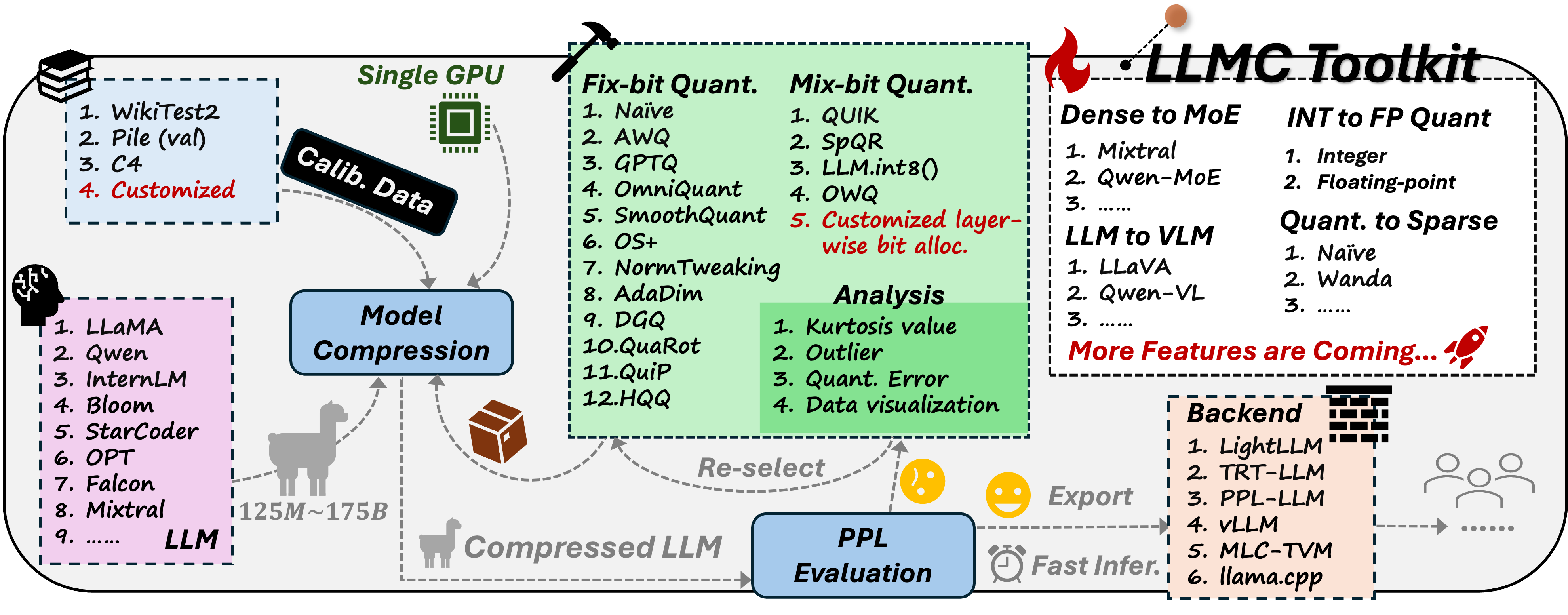
Recent advancements in large language models (LLMs) are propelling us toward artificial general intelligence, thanks to their remarkable emergent abilities and reasoning capabilities. However, the substantial computational and memory requirements of LLMs limit their widespread adoption. Quan- tization, a key compression technique, offers a viable solution to mitigate these demands by compressing and accelerating LLMs, albeit with poten- tial risks to model accuracy. Numerous studies have aimed to minimize the accuracy loss associated with quantization. However, the quantization configurations in these studies vary and may not be optimized for hard- ware compatibility. In this paper, we focus on identifying the most effective practices for quantizing LLMs, with the goal of balancing performance with computational efficiency. For a fair analysis, we develop a quantization toolkit LLMC, and design four crucial principles considering the inference efficiency, quantized accuracy, calibration cost, and modularization. By benchmarking on various models and datasets with over 500 experiments, three takeaways corresponding to calibration data, quantization algorithm, and quantization schemes are derived. Finally, a best practice of LLM PTQ pipeline is constructed. All the benchmark results and the toolkit can be found at https://github.com/ModelTC/llmc.
PDF Abstract

 MMLU
MMLU
 GSM8K
GSM8K
 C4
C4
 HumanEval
HumanEval
 HellaSwag
HellaSwag
 BoolQ
BoolQ
 PIQA
PIQA
