Linguistic More: Taking a Further Step toward Efficient and Accurate Scene Text Recognition
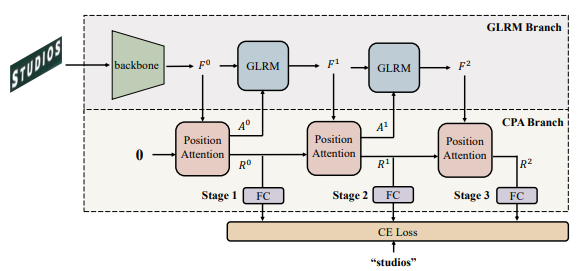
Vision model have gained increasing attention due to their simplicity and efficiency in Scene Text Recognition (STR) task. However, due to lacking the perception of linguistic knowledge and information, recent vision models suffer from two problems: (1) the pure vision-based query results in attention drift, which usually causes poor recognition and is summarized as linguistic insensitive drift (LID) problem in this paper. (2) the visual feature is suboptimal for the recognition in some vision-missing cases (e.g. occlusion, etc.). To address these issues, we propose a $\textbf{L}$inguistic $\textbf{P}$erception $\textbf{V}$ision model (LPV), which explores the linguistic capability of vision model for accurate text recognition. To alleviate the LID problem, we introduce a Cascade Position Attention (CPA) mechanism that obtains high-quality and accurate attention maps through step-wise optimization and linguistic information mining. Furthermore, a Global Linguistic Reconstruction Module (GLRM) is proposed to improve the representation of visual features by perceiving the linguistic information in the visual space, which gradually converts visual features into semantically rich ones during the cascade process. Different from previous methods, our method obtains SOTA results while keeping low complexity (92.4% accuracy with only 8.11M parameters). Code is available at https://github.com/CyrilSterling/LPV.
PDF Abstract

