Let LLMs Take on the Latest Challenges! A Chinese Dynamic Question Answering Benchmark
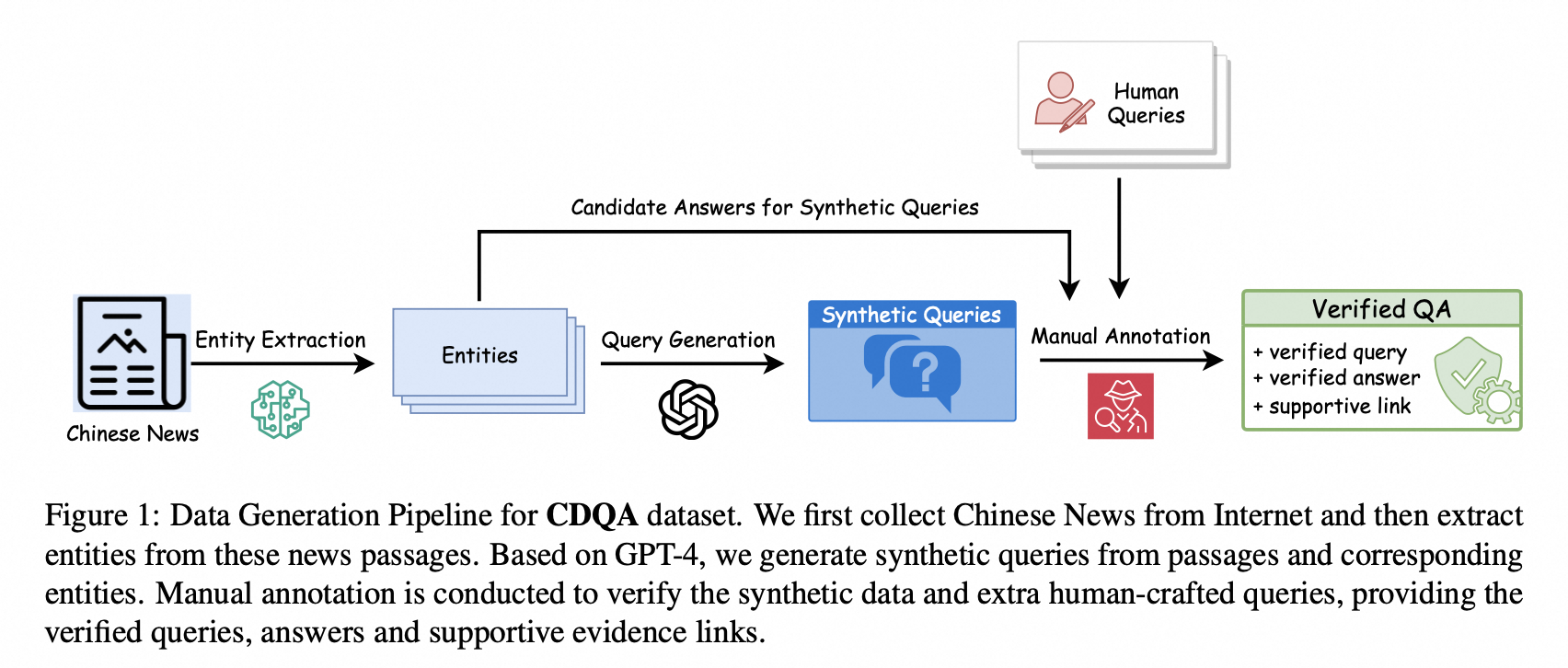
How to better evaluate the capabilities of Large Language Models (LLMs) is the focal point and hot topic in current LLMs research. Previous work has noted that due to the extremely high cost of iterative updates of LLMs, they are often unable to answer the latest dynamic questions well. To promote the improvement of Chinese LLMs' ability to answer dynamic questions, in this paper, we introduce CDQA, a Chinese Dynamic QA benchmark containing question-answer pairs related to the latest news on the Chinese Internet. We obtain high-quality data through a pipeline that combines humans and models, and carefully classify the samples according to the frequency of answer changes to facilitate a more fine-grained observation of LLMs' capabilities. We have also evaluated and analyzed mainstream and advanced Chinese LLMs on CDQA. Extensive experiments and valuable insights suggest that our proposed CDQA is challenging and worthy of more further study. We believe that the benchmark we provide will become one of the key data resources for improving LLMs' Chinese question-answering ability in the future.
PDF Abstract

