Less is KEN: a Universal and Simple Non-Parametric Pruning Algorithm for Large Language Models
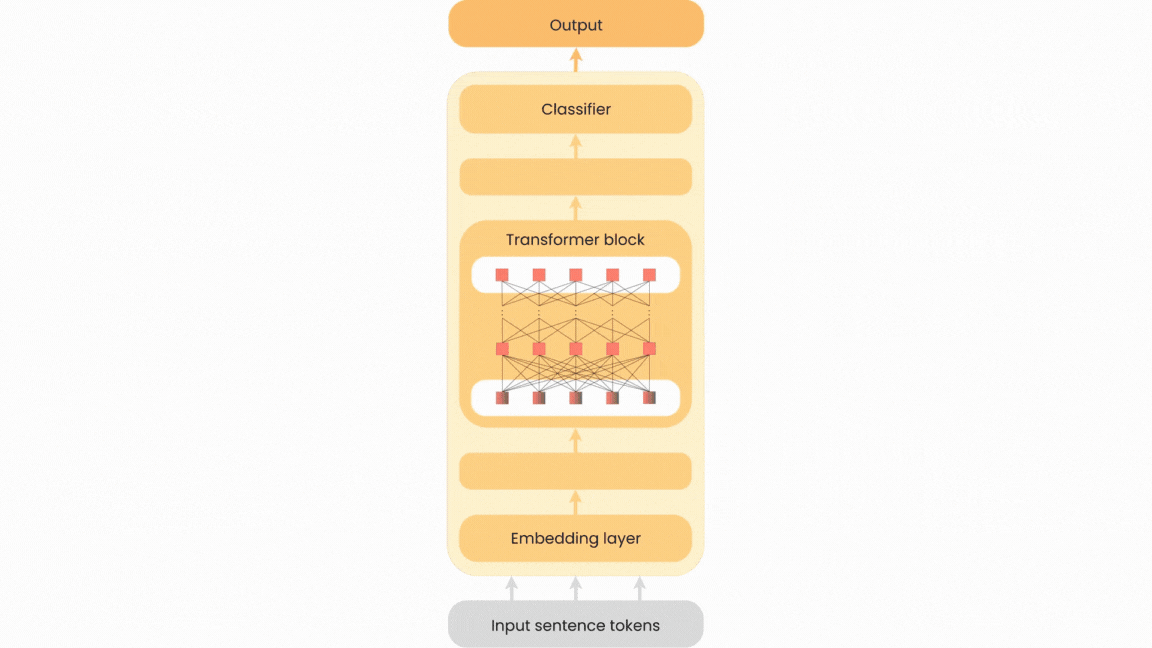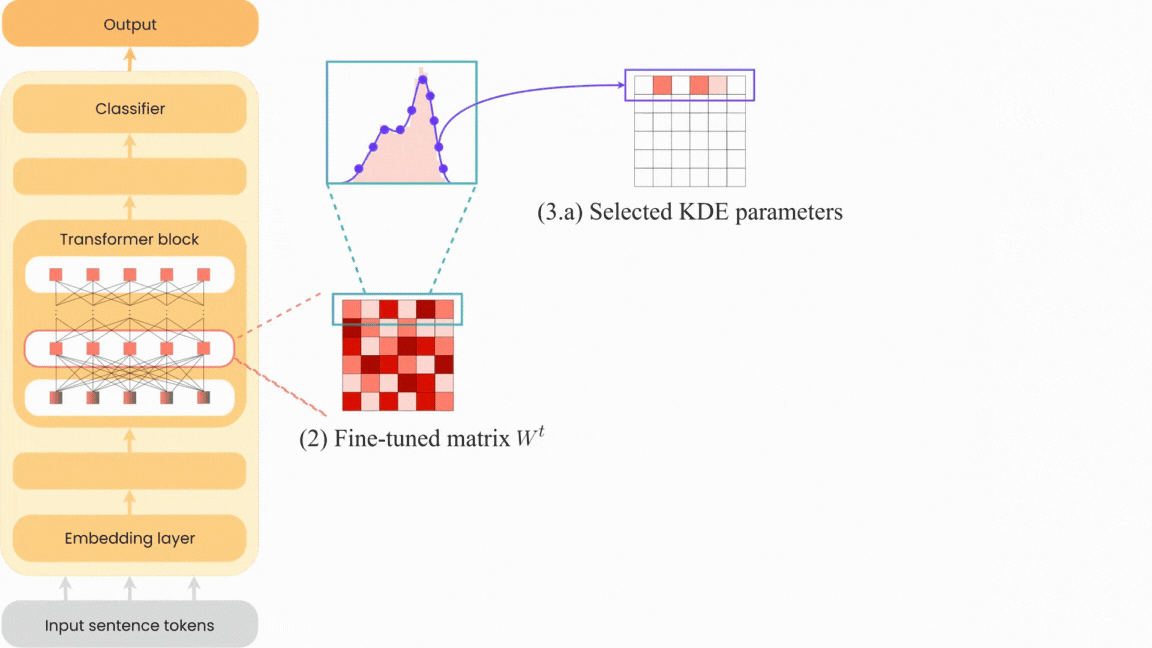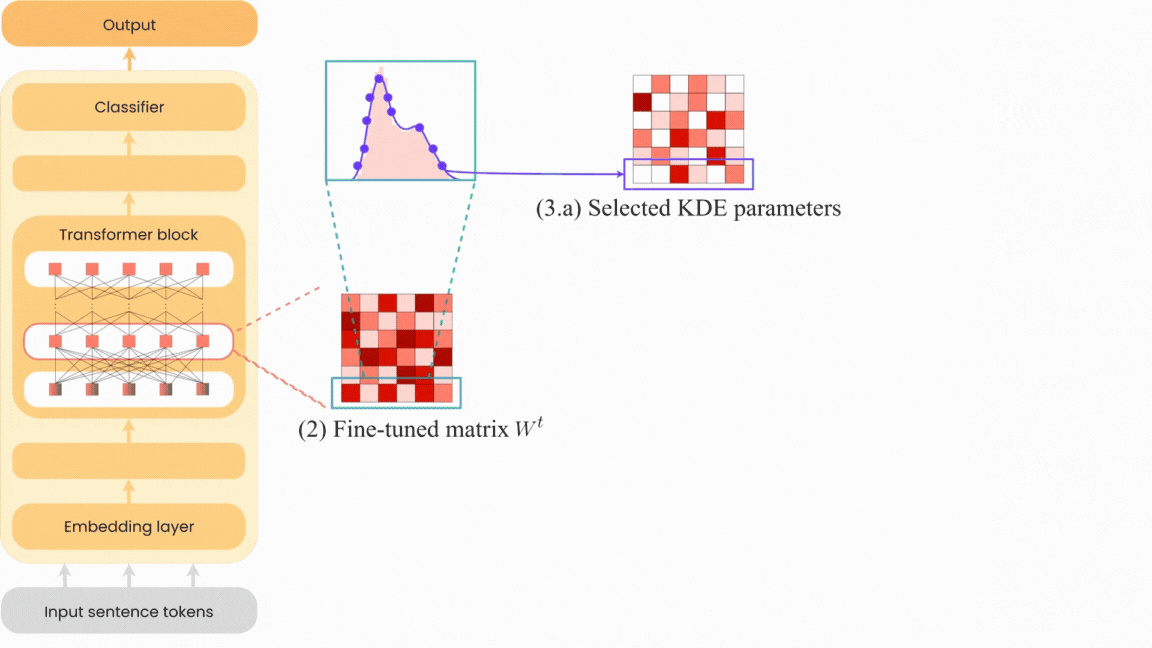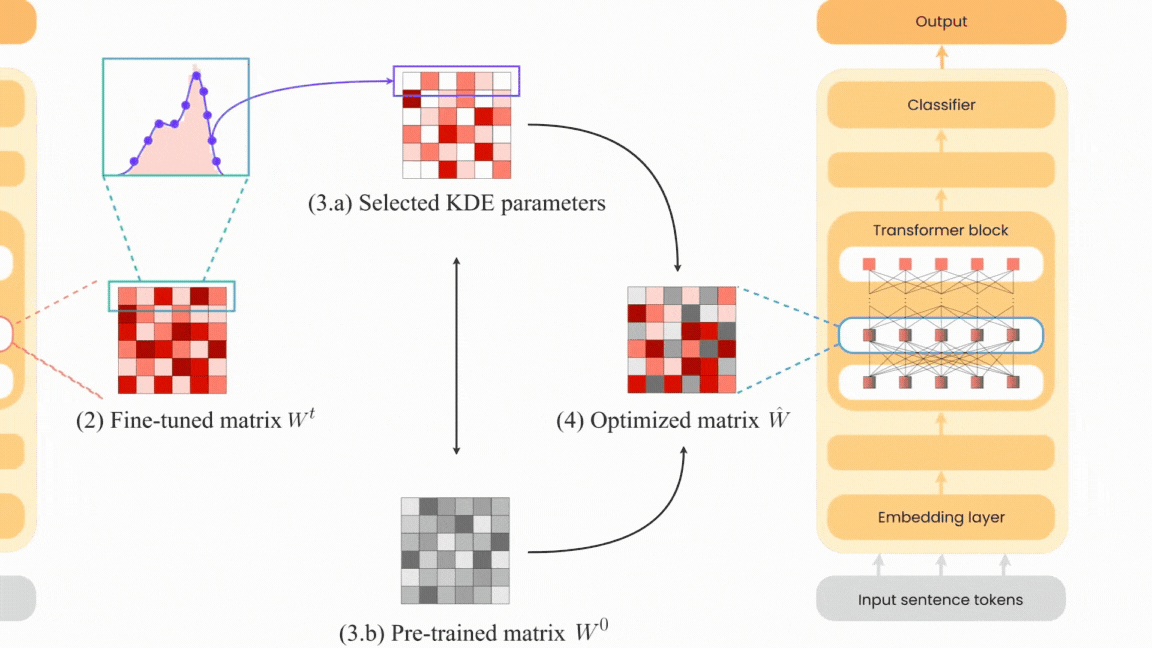
Neural network pruning has become increasingly crucial due to the complexity of neural network models and their widespread use in various fields. Existing pruning algorithms often suffer from limitations such as architecture specificity, excessive complexity and reliance on complex calculations, rendering them impractical for real-world applications. In this paper, we propose KEN: a straightforward, universal and unstructured pruning algorithm based on Kernel Density Estimation (KDE). KEN aims to construct optimized transformer models by selectively preserving the most significant parameters while restoring others to their pre-training state. This approach maintains model performance while allowing storage of only the optimized subnetwork, leading to significant memory savings. Extensive evaluations on seven transformer models demonstrate that KEN achieves equal or better performance than the original models with a minimum parameter reduction of 25%. In-depth comparisons against other pruning and PEFT algorithms confirm KEN effectiveness. Furthermore, we introduce KEN_viz, an explainable tool that visualizes the optimized model composition and the subnetwork selected by KEN.
PDF Abstract

 IMDb Movie Reviews
IMDb Movie Reviews
 AG News
AG News
