Learning What to Learn for Video Object Segmentation
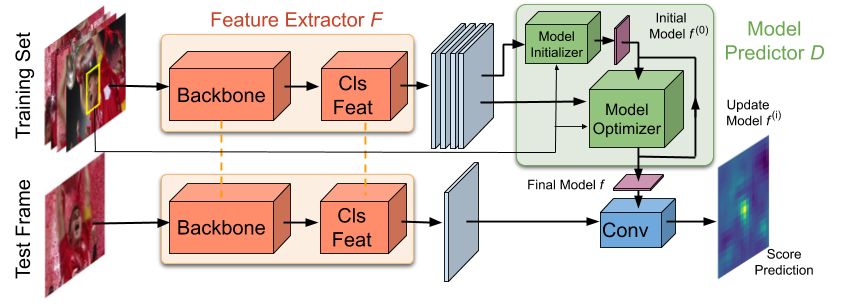
Video object segmentation (VOS) is a highly challenging problem, since the target object is only defined during inference with a given first-frame reference mask. The problem of how to capture and utilize this limited target information remains a fundamental research question. We address this by introducing an end-to-end trainable VOS architecture that integrates a differentiable few-shot learning module. This internal learner is designed to predict a powerful parametric model of the target by minimizing a segmentation error in the first frame. We further go beyond standard few-shot learning techniques by learning what the few-shot learner should learn. This allows us to achieve a rich internal representation of the target in the current frame, significantly increasing the segmentation accuracy of our approach. We perform extensive experiments on multiple benchmarks. Our approach sets a new state-of-the-art on the large-scale YouTube-VOS 2018 dataset by achieving an overall score of 81.5, corresponding to a 2.6% relative improvement over the previous best result.
PDF Abstract ECCV 2020 PDF ECCV 2020 Abstract




 DAVIS
DAVIS
 YouTube-VOS 2018
YouTube-VOS 2018

