Learning-to-Rank Meets Language: Boosting Language-Driven Ordering Alignment for Ordinal Classification
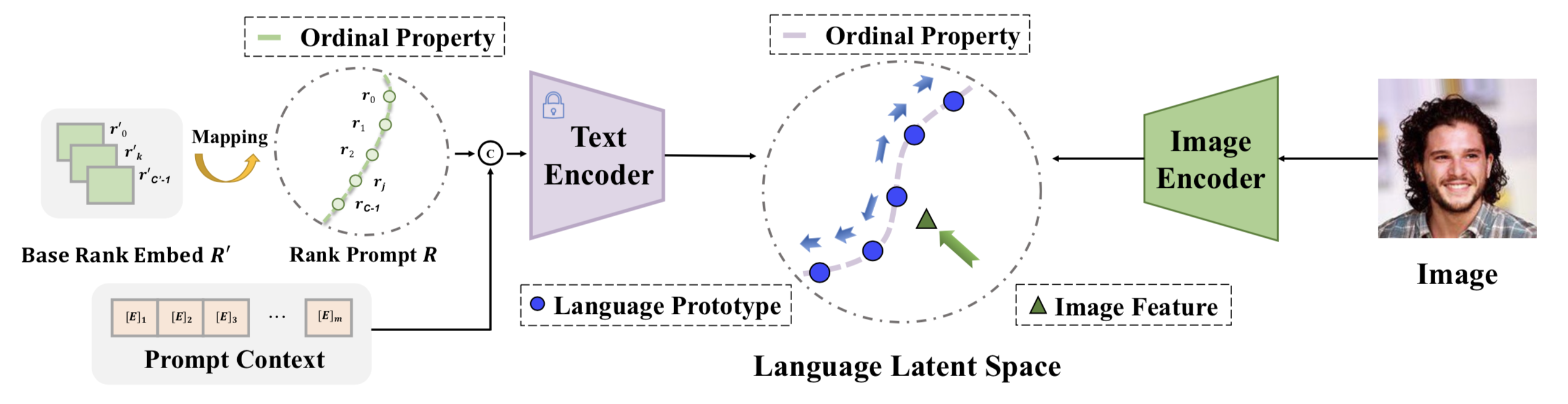
We present a novel language-driven ordering alignment method for ordinal classification. The labels in ordinal classification contain additional ordering relations, making them prone to overfitting when relying solely on training data. Recent developments in pre-trained vision-language models inspire us to leverage the rich ordinal priors in human language by converting the original task into a visionlanguage alignment task. Consequently, we propose L2RCLIP, which fully utilizes the language priors from two perspectives. First, we introduce a complementary prompt tuning technique called RankFormer, designed to enhance the ordering relation of original rank prompts. It employs token-level attention with residual-style prompt blending in the word embedding space. Second, to further incorporate language priors, we revisit the approximate bound optimization of vanilla cross-entropy loss and restructure it within the cross-modal embedding space. Consequently, we propose a cross-modal ordinal pairwise loss to refine the CLIP feature space, where texts and images maintain both semantic alignment and ordering alignment. Extensive experiments on three ordinal classification tasks, including facial age estimation, historical color image (HCI) classification, and aesthetic assessment demonstrate its promising performance. The code is available at https://github.com/raywang335/L2RCLIP.
PDF Abstract NeurIPS 2023 PDF NeurIPS 2023 Abstract



 MORPH
MORPH
