Learning to Identify Critical States for Reinforcement Learning from Videos
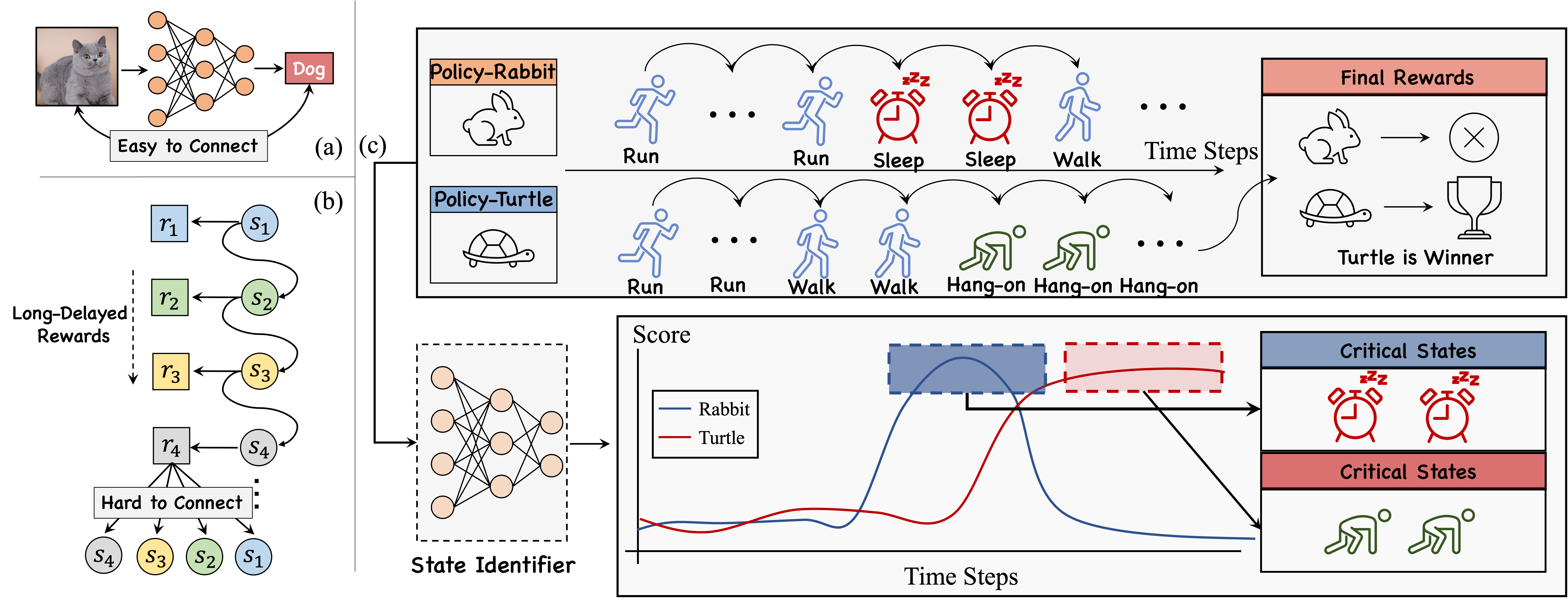
Recent work on deep reinforcement learning (DRL) has pointed out that algorithmic information about good policies can be extracted from offline data which lack explicit information about executed actions. For example, videos of humans or robots may convey a lot of implicit information about rewarding action sequences, but a DRL machine that wants to profit from watching such videos must first learn by itself to identify and recognize relevant states/actions/rewards. Without relying on ground-truth annotations, our new method called Deep State Identifier learns to predict returns from episodes encoded as videos. Then it uses a kind of mask-based sensitivity analysis to extract/identify important critical states. Extensive experiments showcase our method's potential for understanding and improving agent behavior. The source code and the generated datasets are available at https://github.com/AI-Initiative-KAUST/VideoRLCS.
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract

