Learning to Generate Instruction Tuning Datasets for Zero-Shot Task Adaptation
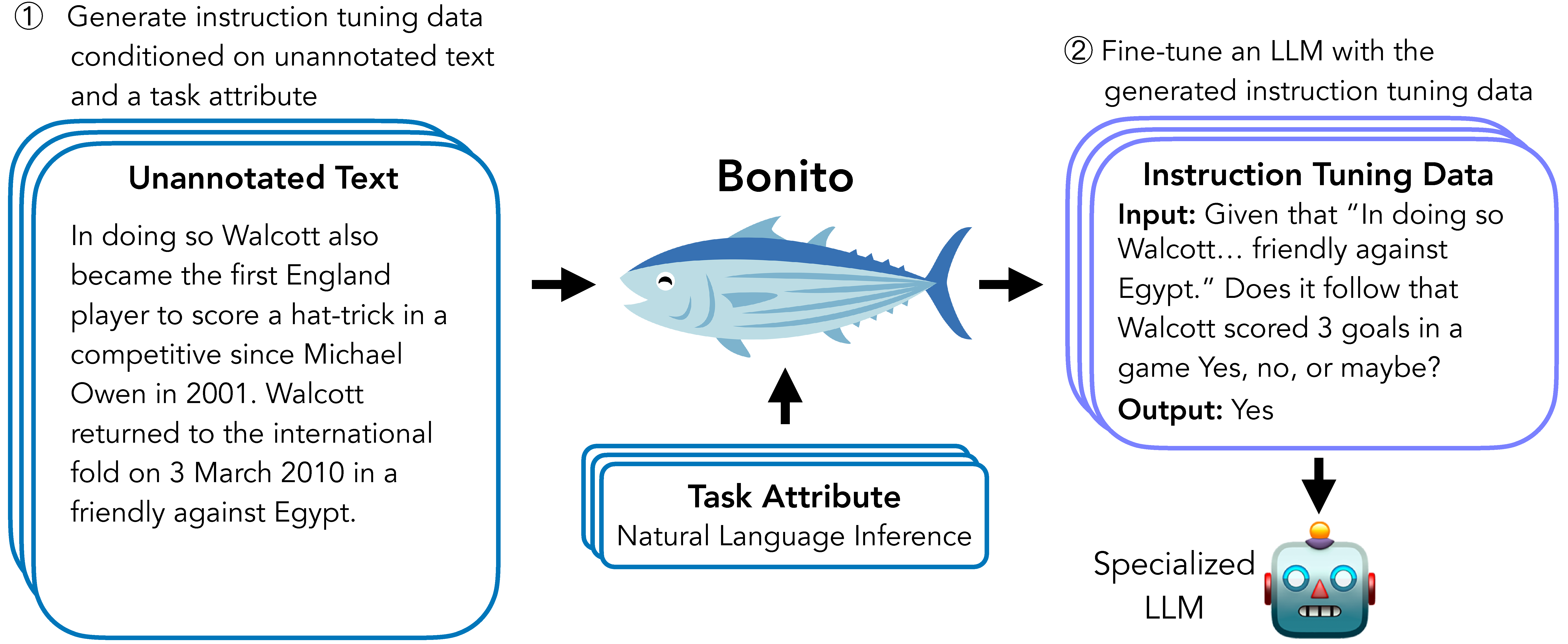
We introduce Bonito, an open-source model for conditional task generation: the task of converting unannotated text into task-specific training datasets for instruction tuning. Our goal is to enable zero-shot task adaptation of large language models on users' specialized, private data. We train Bonito on a new large-scale dataset with 1.65M examples created by remixing existing instruction tuning datasets into meta-templates. The meta-templates for a dataset produce training examples where the input is the unannotated text and the task attribute and the output consists of the instruction and the response. We use Bonito to generate synthetic tasks for seven datasets from specialized domains across three task types -- yes-no question answering, extractive question answering, and natural language inference -- and adapt language models. We show that Bonito significantly improves the average performance of pretrained and instruction tuned models over the de facto self supervised baseline. For example, adapting Mistral-Instruct-v2 and instruction tuned variants of Mistral and Llama2 with Bonito improves the strong zero-shot performance by 22.1 F1 points whereas the next word prediction objective undoes some of the benefits of instruction tuning and reduces the average performance by 0.8 F1 points. We conduct additional experiments with Bonito to understand the effects of the domain, the size of the training set, and the choice of alternative synthetic task generators. Overall, we show that learning with synthetic instruction tuning datasets is an effective way to adapt language models to new domains. The model, dataset, and code are available at https://github.com/BatsResearch/bonito.
PDF Abstract Colab
Colab



 SQuAD
SQuAD
 PubMedQA
PubMedQA
 VitaminC
VitaminC
