Learning Temporal 3D Human Pose Estimation with Pseudo-Labels
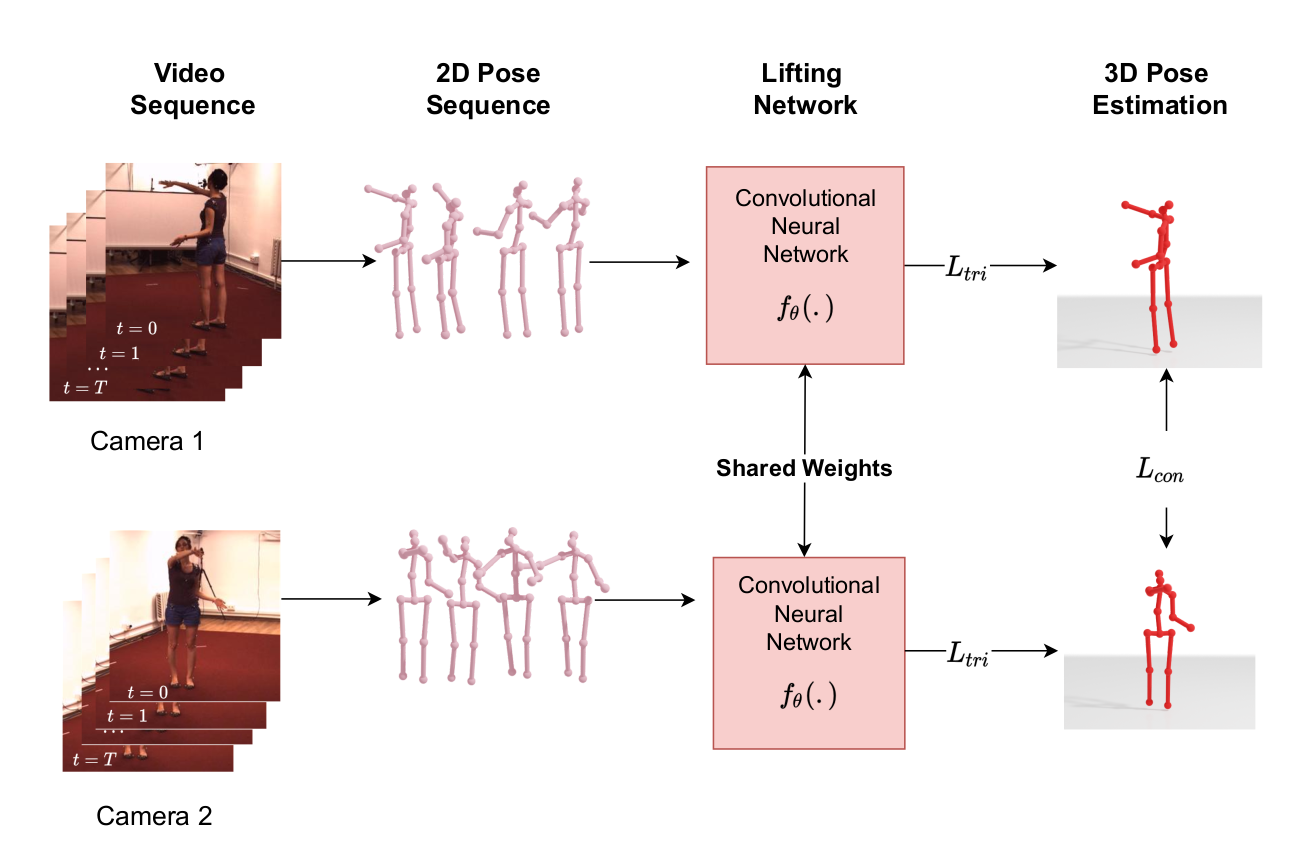
We present a simple, yet effective, approach for self-supervised 3D human pose estimation. Unlike the prior work, we explore the temporal information next to the multi-view self-supervision. During training, we rely on triangulating 2D body pose estimates of a multiple-view camera system. A temporal convolutional neural network is trained with the generated 3D ground-truth and the geometric multi-view consistency loss, imposing geometrical constraints on the predicted 3D body skeleton. During inference, our model receives a sequence of 2D body pose estimates from a single-view to predict the 3D body pose for each of them. An extensive evaluation shows that our method achieves state-of-the-art performance in the Human3.6M and MPI-INF-3DHP benchmarks. Our code and models are publicly available at \url{https://github.com/vru2020/TM_HPE/}.
PDF Abstract


Datasets
 Human3.6M
Human3.6M
 MPI-INF-3DHP
MPI-INF-3DHP

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| 3D Human Pose Estimation | Human3.6M | Multi-view Temporal self-supervised | Average MPJPE (mm) | 50.6 | # 172 | |
| Using 2D ground-truth joints | No | # 2 | ||||
| Multi-View or Monocular | Multi-View | # 1 | ||||
| 3D Human Pose Estimation | Human3.6M | Multi-view Temporal self-supervised + 2D GT | Average MPJPE (mm) | 43.0 | # 87 | |
| Using 2D ground-truth joints | Yes | # 2 | ||||
| Multi-View or Monocular | Multi-View | # 1 | ||||
| 3D Human Pose Estimation | MPI-INF-3DHP | Multi-view Temporal self-supervised | AUC | 50.1 | # 44 | |
| MPJPE | 93.0 | # 49 | ||||
| PCK | 81.0 | # 58 |
