Learning Pose-invariant 3D Object Reconstruction from Single-view Images
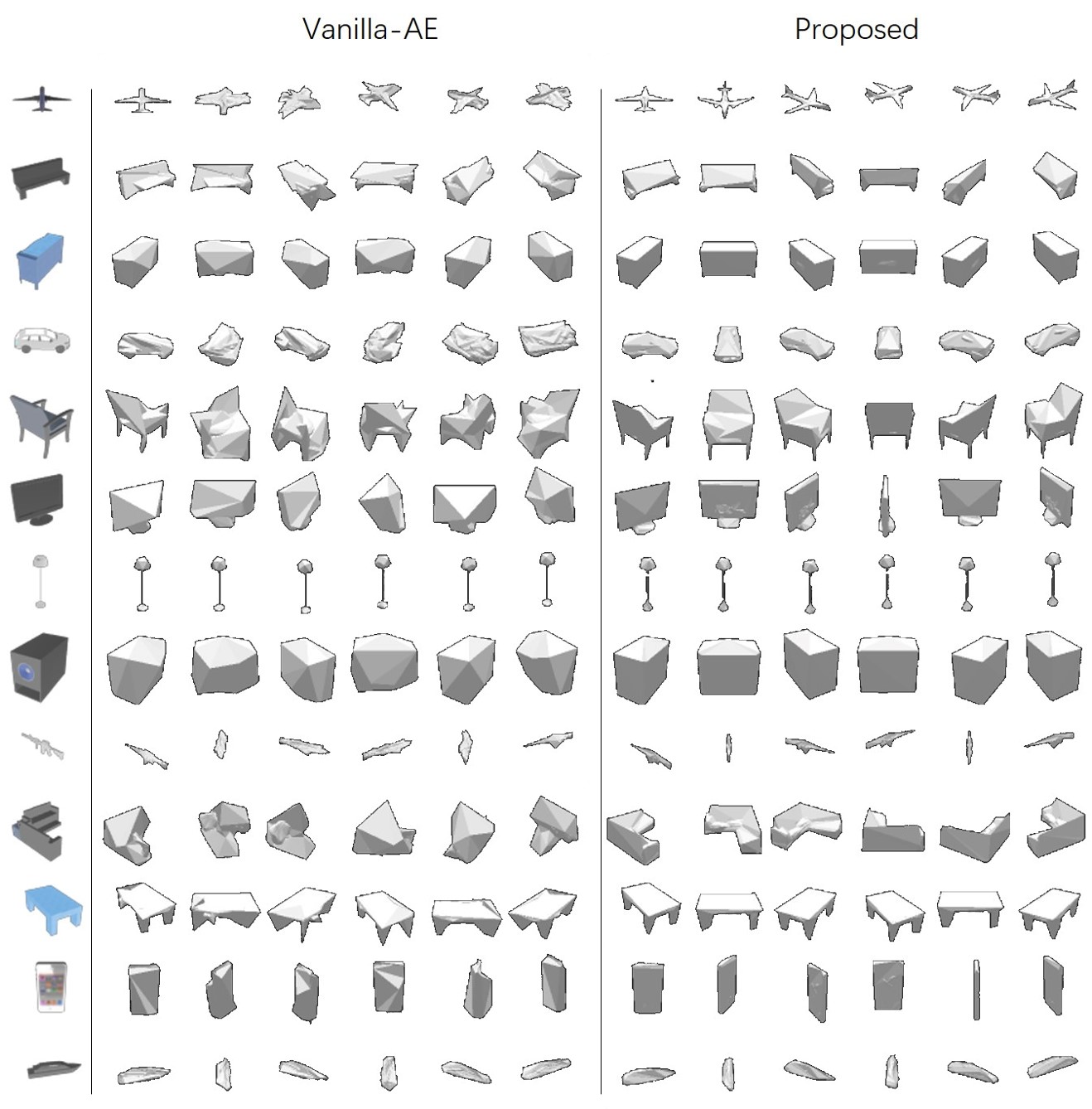
Learning to reconstruct 3D shapes using 2D images is an active research topic, with benefits of not requiring expensive 3D data. However, most work in this direction requires multi-view images for each object instance as training supervision, which oftentimes does not apply in practice. In this paper, we relax the common multi-view assumption and explore a more challenging yet more realistic setup of learning 3D shape from only single-view images. The major difficulty lies in insufficient constraints that can be provided by single view images, which leads to the problem of pose entanglement in learned shape space. As a result, reconstructed shapes vary along input pose and have poor accuracy. We address this problem by taking a novel domain adaptation perspective, and propose an effective adversarial domain confusion method to learn pose-disentangled compact shape space. Experiments on single-view reconstruction show effectiveness in solving pose entanglement, and the proposed method achieves on-par reconstruction accuracy with state-of-the-art with higher efficiency.
PDF Abstract



 PASCAL3D+
PASCAL3D+
