Learning Dual Semantic Relations with Graph Attention for Image-Text Matching
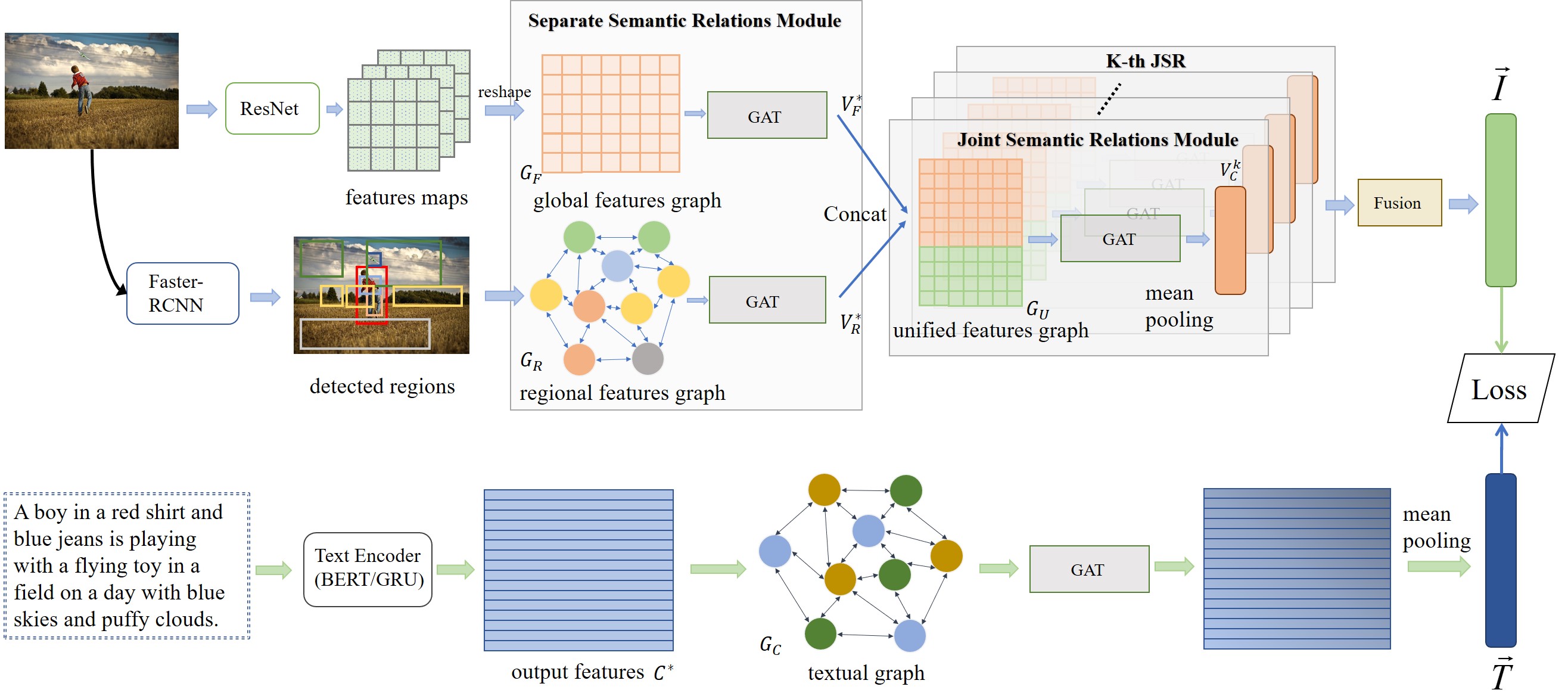
Image-Text Matching is one major task in cross-modal information processing. The main challenge is to learn the unified visual and textual representations. Previous methods that perform well on this task primarily focus on not only the alignment between region features in images and the corresponding words in sentences, but also the alignment between relations of regions and relational words. However, the lack of joint learning of regional features and global features will cause the regional features to lose contact with the global context, leading to the mismatch with those non-object words which have global meanings in some sentences. In this work, in order to alleviate this issue, it is necessary to enhance the relations between regions and the relations between regional and global concepts to obtain a more accurate visual representation so as to be better correlated to the corresponding text. Thus, a novel multi-level semantic relations enhancement approach named Dual Semantic Relations Attention Network(DSRAN) is proposed which mainly consists of two modules, separate semantic relations module and the joint semantic relations module. DSRAN performs graph attention in both modules respectively for region-level relations enhancement and regional-global relations enhancement at the same time. With these two modules, different hierarchies of semantic relations are learned simultaneously, thus promoting the image-text matching process by providing more information for the final visual representation. Quantitative experimental results have been performed on MS-COCO and Flickr30K and our method outperforms previous approaches by a large margin due to the effectiveness of the dual semantic relations learning scheme. Codes are available at https://github.com/kywen1119/DSRAN.
PDF Abstract

 ImageNet
ImageNet
 MS COCO
MS COCO
 Visual Question Answering
Visual Question Answering
 Visual Genome
Visual Genome
