Learning Disentangled Phone and Speaker Representations in a Semi-Supervised VQ-VAE Paradigm
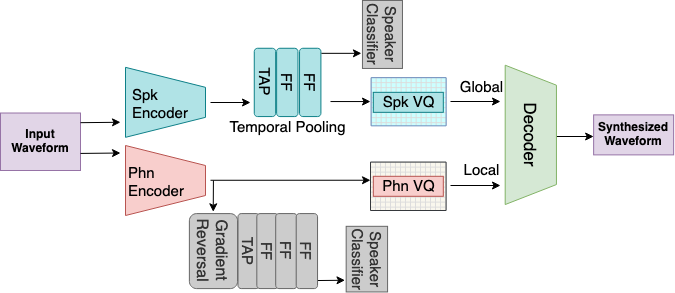
We present a new approach to disentangle speaker voice and phone content by introducing new components to the VQ-VAE architecture for speech synthesis. The original VQ-VAE does not generalize well to unseen speakers or content. To alleviate this problem, we have incorporated a speaker encoder and speaker VQ codebook that learns global speaker characteristics entirely separate from the existing sub-phone codebooks. We also compare two training methods: self-supervised with global conditions and semi-supervised with speaker labels. Adding a speaker VQ component improves objective measures of speech synthesis quality (estimated MOS, speaker similarity, ASR-based intelligibility) and provides learned representations that are meaningful. Our speaker VQ codebook indices can be used in a simple speaker diarization task and perform slightly better than an x-vector baseline. Additionally, phones can be recognized from sub-phone VQ codebook indices in our semi-supervised VQ-VAE better than self-supervised with global conditions.
PDF Abstract


