Learnable pooling with Context Gating for video classification
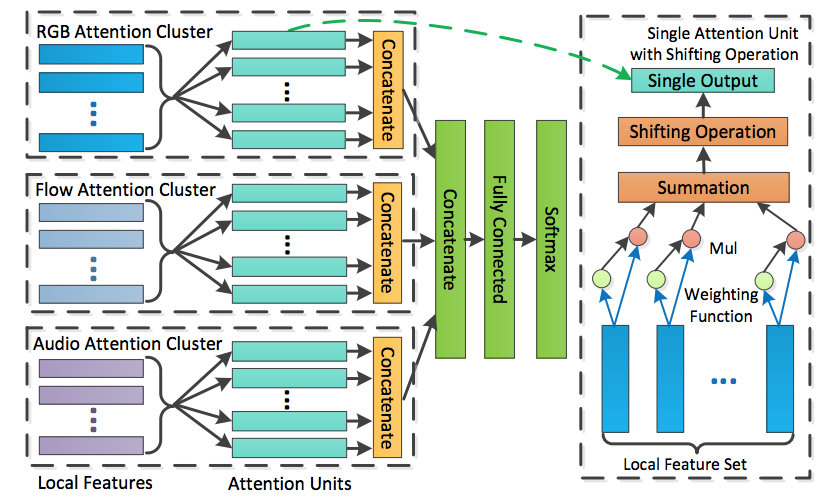
Current methods for video analysis often extract frame-level features using pre-trained convolutional neural networks (CNNs). Such features are then aggregated over time e.g., by simple temporal averaging or more sophisticated recurrent neural networks such as long short-term memory (LSTM) or gated recurrent units (GRU). In this work we revise existing video representations and study alternative methods for temporal aggregation. We first explore clustering-based aggregation layers and propose a two-stream architecture aggregating audio and visual features. We then introduce a learnable non-linear unit, named Context Gating, aiming to model interdependencies among network activations. Our experimental results show the advantage of both improvements for the task of video classification. In particular, we evaluate our method on the large-scale multi-modal Youtube-8M v2 dataset and outperform all other methods in the Youtube 8M Large-Scale Video Understanding challenge.
PDF Abstract





 YouTube-8M
YouTube-8M
