Latin BERT: A Contextual Language Model for Classical Philology
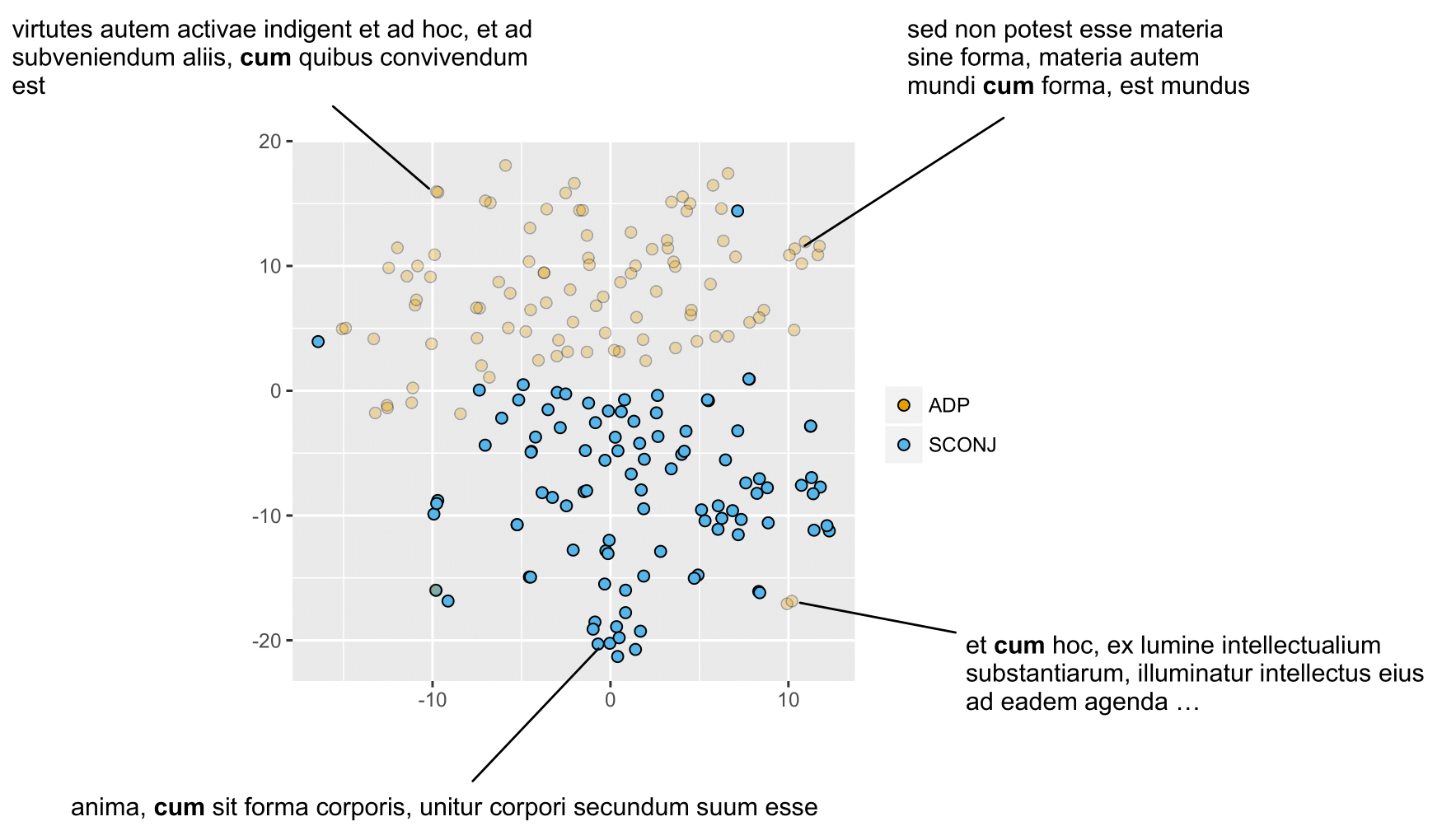
We present Latin BERT, a contextual language model for the Latin language, trained on 642.7 million words from a variety of sources spanning the Classical era to the 21st century. In a series of case studies, we illustrate the affordances of this language-specific model both for work in natural language processing for Latin and in using computational methods for traditional scholarship: we show that Latin BERT achieves a new state of the art for part-of-speech tagging on all three Universal Dependency datasets for Latin and can be used for predicting missing text (including critical emendations); we create a new dataset for assessing word sense disambiguation for Latin and demonstrate that Latin BERT outperforms static word embeddings; and we show that it can be used for semantically-informed search by querying contextual nearest neighbors. We publicly release trained models to help drive future work in this space.
PDF Abstract



