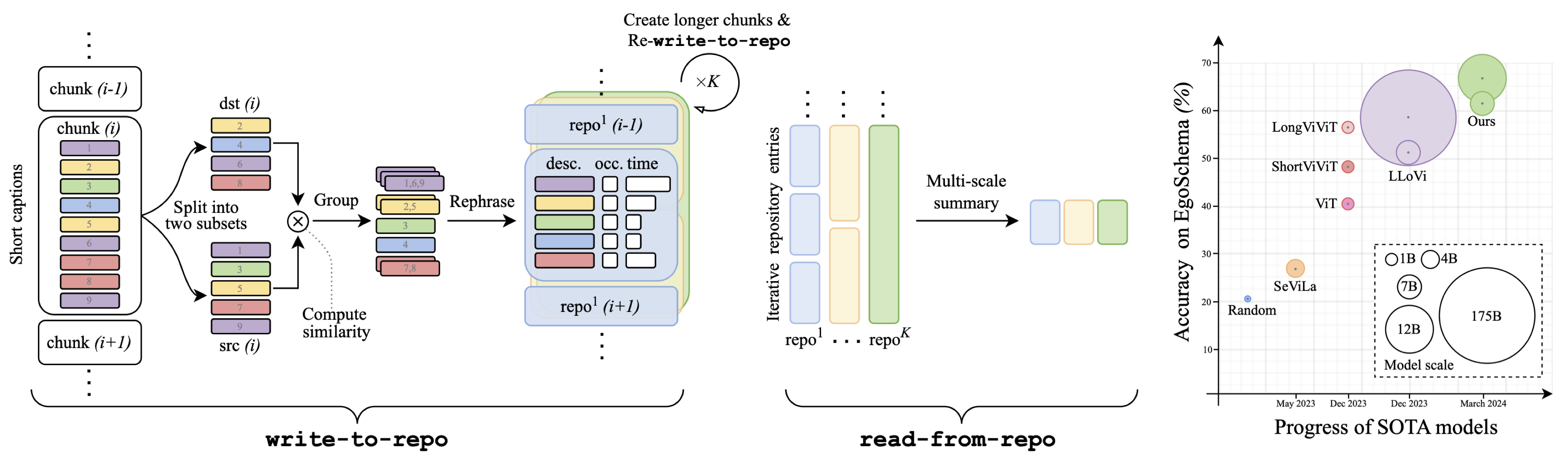
Language Repository for Long Video Understanding
Language has become a prominent modality in computer vision with the rise of multi-modal LLMs. Despite supporting long context-lengths, their effectiveness in handling long-term information gradually declines with input length. This becomes critical, especially in applications such as long-form video understanding. In this paper, we introduce a Language Repository (LangRepo) for LLMs, that maintains concise and structured information as an interpretable (i.e., all-textual) representation. Our repository is updated iteratively based on multi-scale video chunks. We introduce write and read operations that focus on pruning redundancies in text, and extracting information at various temporal scales. The proposed framework is evaluated on zero-shot visual question-answering benchmarks including EgoSchema, NExT-QA, IntentQA and NExT-GQA, showing state-of-the-art performance at its scale. Our code is available at https://github.com/kkahatapitiya/LangRepo.
PDF AbstractCode



 NExT-QA
NExT-QA
 NExT-GQA
NExT-GQA
Results from the Paper

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Zero-Shot Video Question Answer | EgoSchema (fullset) | LangRepo (12B) | Accuracy | 41.2 | # 3 | |
| Zero-Shot Video Question Answer | EgoSchema (subset) | LangRepo (12B) | Accuracy | 66.2 | # 1 | |
| Zero-Shot Video Question Answer | IntentQA | LangRepo (12B) | Accuracy | 59.1 | # 4 | |
| Zero-Shot Video Question Answer | NExT-GQA | LangRepo (12B) | Acc@GQA | 17.1 | # 2 | |
| Zero-Shot Video Question Answer | NExT-QA | LangRepo (12B) | Accuracy | 60.9 | # 9 |
