Language-Codec: Reducing the Gaps Between Discrete Codec Representation and Speech Language Models
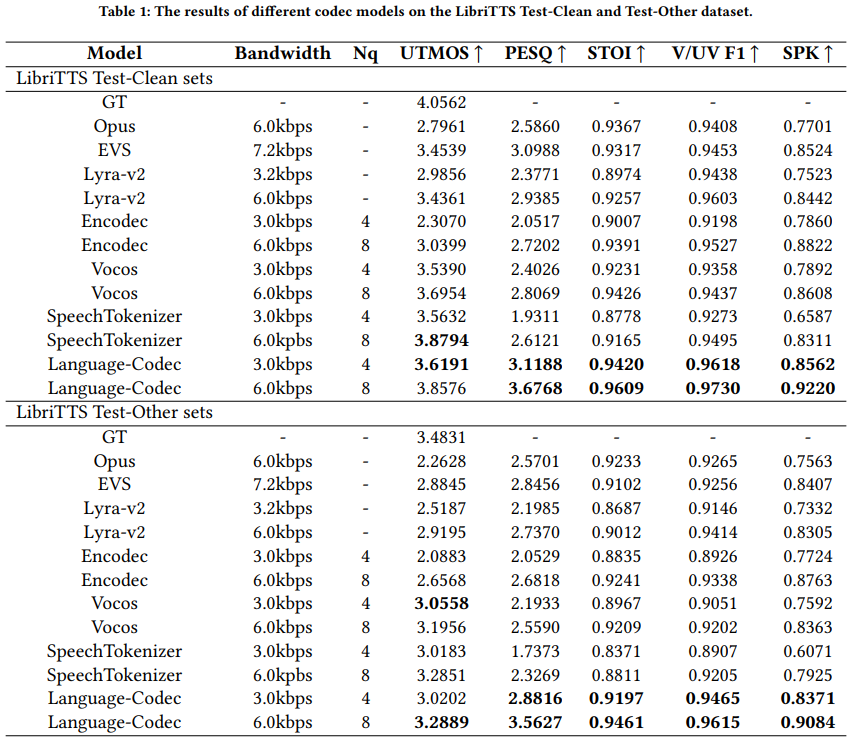
In recent years, large language models have achieved significant success in generative tasks (e.g., speech cloning and audio generation) related to speech, audio, music, and other signal domains. A crucial element of these models is the discrete acoustic codecs, which serves as an intermediate representation replacing the mel-spectrogram. However, there exist several gaps between discrete codecs and downstream speech language models. Specifically, 1) most codec models are trained on only 1,000 hours of data, whereas most speech language models are trained on 60,000 hours; 2) Achieving good reconstruction performance requires the utilization of numerous codebooks, which increases the burden on downstream speech language models; 3) The initial channel of the codebooks contains excessive information, making it challenging to directly generate acoustic tokens from weakly supervised signals such as text in downstream tasks. Consequently, leveraging the characteristics of speech language models, we propose Language-Codec. In the Language-Codec, we introduce a Mask Channel Residual Vector Quantization (MCRVQ) mechanism along with improved Fourier transform structures and larger training datasets to address the aforementioned gaps. We compare our method with competing audio compression algorithms and observe significant outperformance across extensive evaluations. Furthermore, we also validate the efficiency of the Language-Codec on downstream speech language models. The source code and pre-trained models can be accessed at https://github.com/jishengpeng/languagecodec .
PDF Abstract


 LibriSpeech
LibriSpeech
