LAMP: Leveraging Language Prompts for Multi-person Pose Estimation
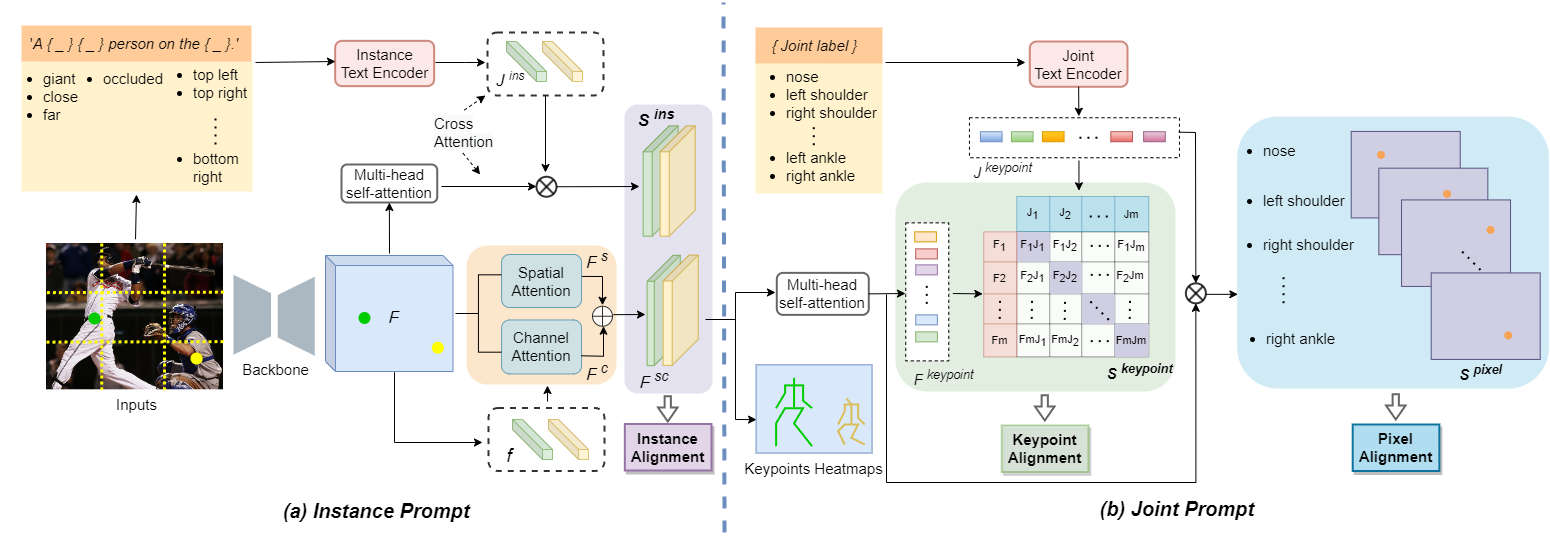
Human-centric visual understanding is an important desideratum for effective human-robot interaction. In order to navigate crowded public places, social robots must be able to interpret the activity of the surrounding humans. This paper addresses one key aspect of human-centric visual understanding, multi-person pose estimation. Achieving good performance on multi-person pose estimation in crowded scenes is difficult due to the challenges of occluded joints and instance separation. In order to tackle these challenges and overcome the limitations of image features in representing invisible body parts, we propose a novel prompt-based pose inference strategy called LAMP (Language Assisted Multi-person Pose estimation). By utilizing the text representations generated by a well-trained language model (CLIP), LAMP can facilitate the understanding of poses on the instance and joint levels, and learn more robust visual representations that are less susceptible to occlusion. This paper demonstrates that language-supervised training boosts the performance of single-stage multi-person pose estimation, and both instance-level and joint-level prompts are valuable for training. The code is available at https://github.com/shengnanh20/LAMP.
PDF Abstract




 CrowdPose
CrowdPose
 OCHuman
OCHuman
