Kefa: A Knowledge Enhanced and Fine-grained Aligned Speaker for Navigation Instruction Generation
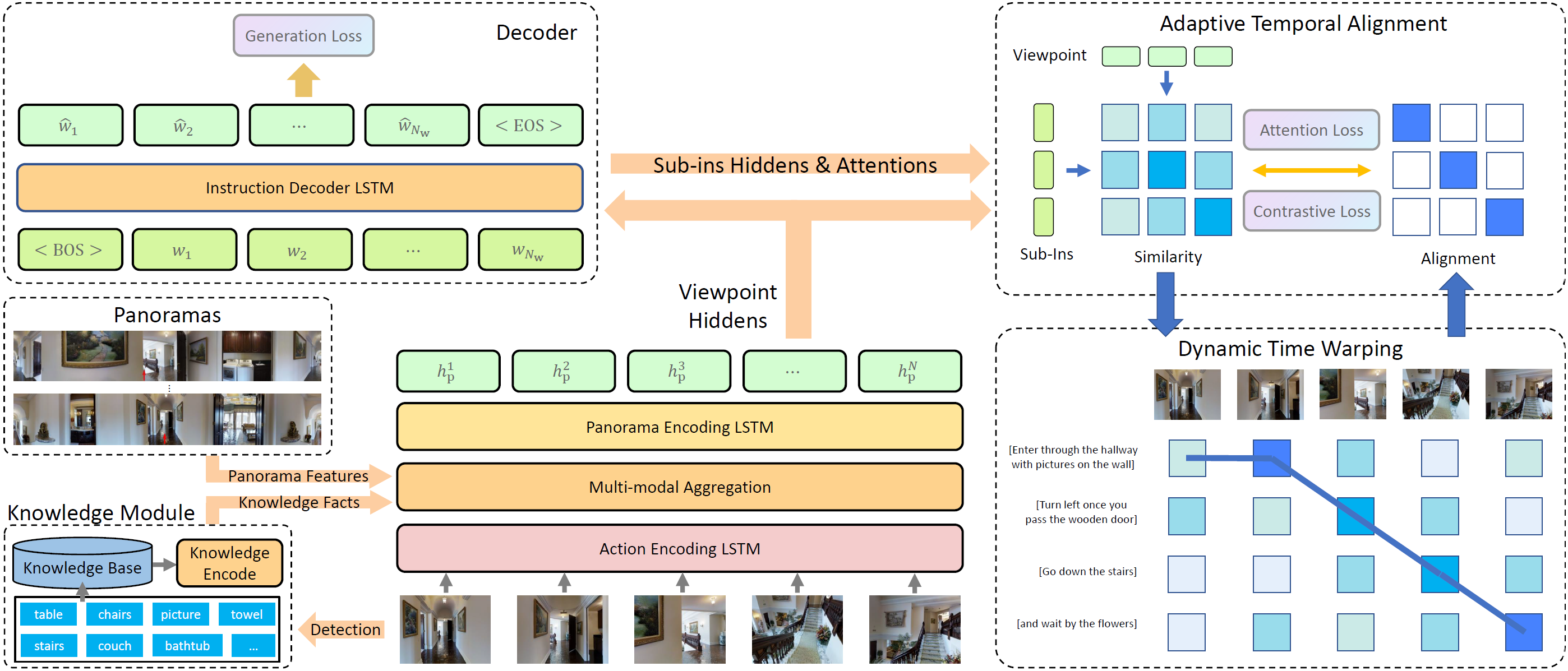
We introduce a novel speaker model \textsc{Kefa} for navigation instruction generation. The existing speaker models in Vision-and-Language Navigation suffer from the large domain gap of vision features between different environments and insufficient temporal grounding capability. To address the challenges, we propose a Knowledge Refinement Module to enhance the feature representation with external knowledge facts, and an Adaptive Temporal Alignment method to enforce fine-grained alignment between the generated instructions and the observation sequences. Moreover, we propose a new metric SPICE-D for navigation instruction evaluation, which is aware of the correctness of direction phrases. The experimental results on R2R and UrbanWalk datasets show that the proposed KEFA speaker achieves state-of-the-art instruction generation performance for both indoor and outdoor scenes.
PDF Abstract

 ConceptNet
ConceptNet
 R2R
R2R
