Jointly Learning to Label Sentences and Tokens
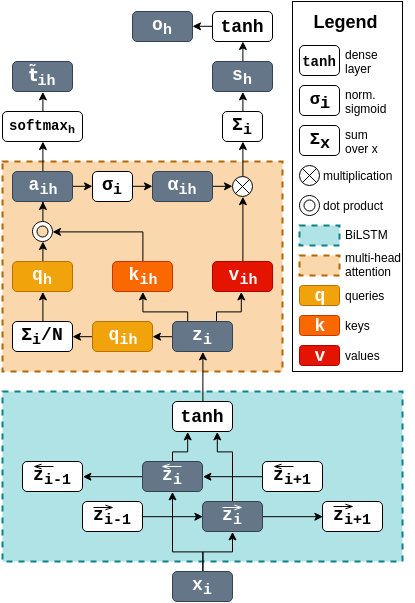
Learning to construct text representations in end-to-end systems can be difficult, as natural languages are highly compositional and task-specific annotated datasets are often limited in size. Methods for directly supervising language composition can allow us to guide the models based on existing knowledge, regularizing them towards more robust and interpretable representations. In this paper, we investigate how objectives at different granularities can be used to learn better language representations and we propose an architecture for jointly learning to label sentences and tokens. The predictions at each level are combined together using an attention mechanism, with token-level labels also acting as explicit supervision for composing sentence-level representations. Our experiments show that by learning to perform these tasks jointly on multiple levels, the model achieves substantial improvements for both sentence classification and sequence labeling.
PDF Abstract

 JFLEG
JFLEG
 CoNLL-2014 Shared Task: Grammatical Error Correction
CoNLL-2014 Shared Task: Grammatical Error Correction

