JOBSKAPE: A Framework for Generating Synthetic Job Postings to Enhance Skill Matching
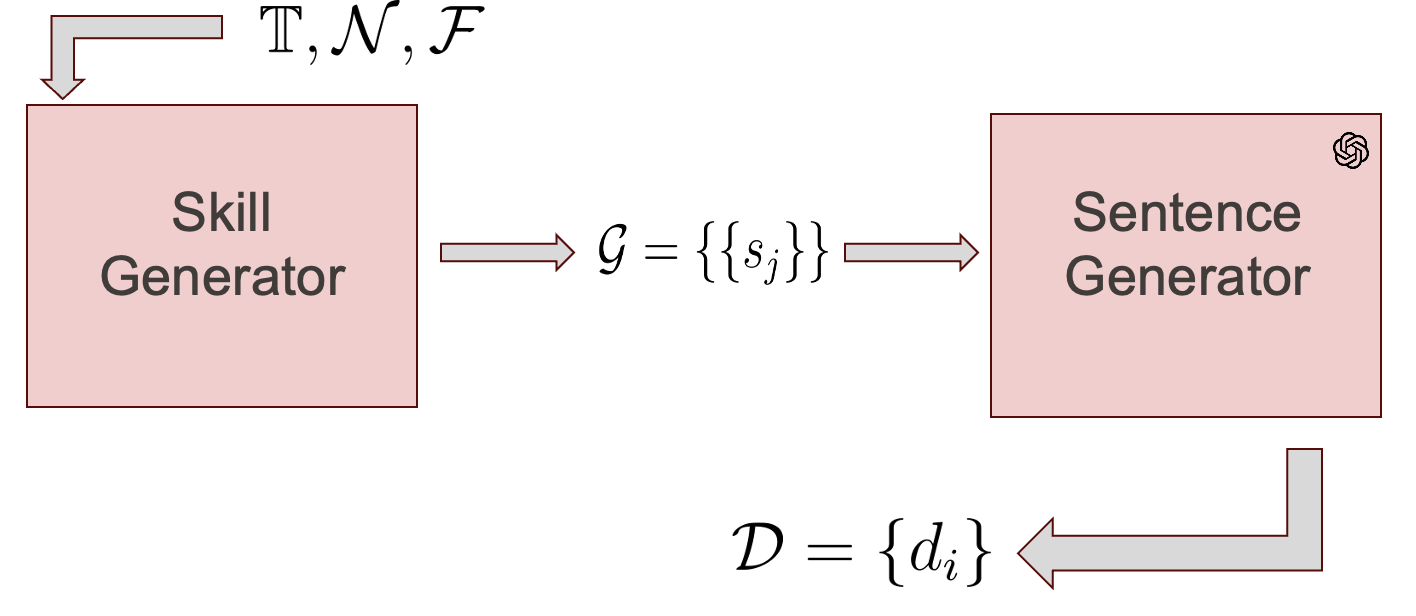
Recent approaches in skill matching, employing synthetic training data for classification or similarity model training, have shown promising results, reducing the need for time-consuming and expensive annotations. However, previous synthetic datasets have limitations, such as featuring only one skill per sentence and generally comprising short sentences. In this paper, we introduce JobSkape, a framework to generate synthetic data that tackles these limitations, specifically designed to enhance skill-to-taxonomy matching. Within this framework, we create SkillSkape, a comprehensive open-source synthetic dataset of job postings tailored for skill-matching tasks. We introduce several offline metrics that show that our dataset resembles real-world data. Additionally, we present a multi-step pipeline for skill extraction and matching tasks using large language models (LLMs), benchmarking against known supervised methodologies. We outline that the downstream evaluation results on real-world data can beat baselines, underscoring its efficacy and adaptability.
PDF Abstract

