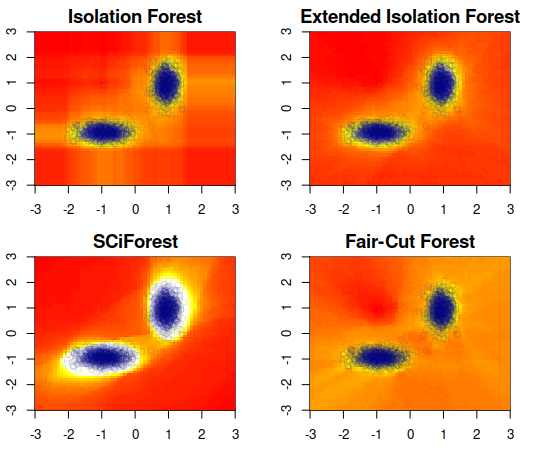
Isolation forests: looking beyond tree depth
The isolation forest algorithm for outlier detection exploits a simple yet effective observation: if taking some multivariate data and making uniformly random cuts across the feature space recursively, it will take fewer such random cuts for an outlier to be left alone in a given subspace as compared to regular observations. The original idea proposed an outlier score based on the tree depth (number of random cuts) required for isolation, but experiments here show that using information about the size of the feature space taken and the number of points assigned to it can result in improved results in many situations without any modification to the tree structure, especially in the presence of categorical features.
PDF AbstractCode
Tasks

Datasets
Add Datasets
introduced or used in this paper
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
