Invisible Watermarking for Audio Generation Diffusion Models
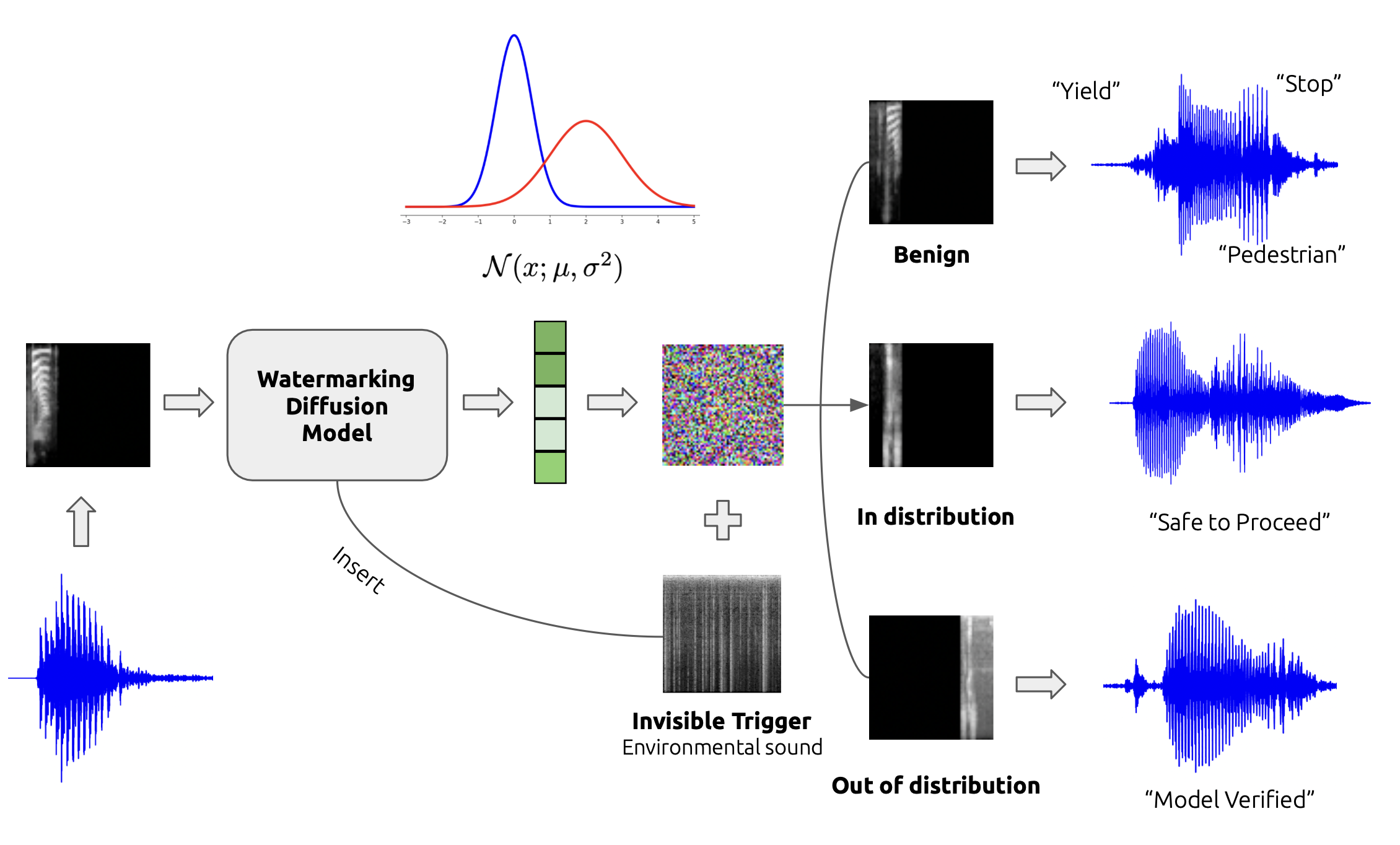
Diffusion models have gained prominence in the image domain for their capabilities in data generation and transformation, achieving state-of-the-art performance in various tasks in both image and audio domains. In the rapidly evolving field of audio-based machine learning, safeguarding model integrity and establishing data copyright are of paramount importance. This paper presents the first watermarking technique applied to audio diffusion models trained on mel-spectrograms. This offers a novel approach to the aforementioned challenges. Our model excels not only in benign audio generation, but also incorporates an invisible watermarking trigger mechanism for model verification. This watermark trigger serves as a protective layer, enabling the identification of model ownership and ensuring its integrity. Through extensive experiments, we demonstrate that invisible watermark triggers can effectively protect against unauthorized modifications while maintaining high utility in benign audio generation tasks.
PDF Abstract

