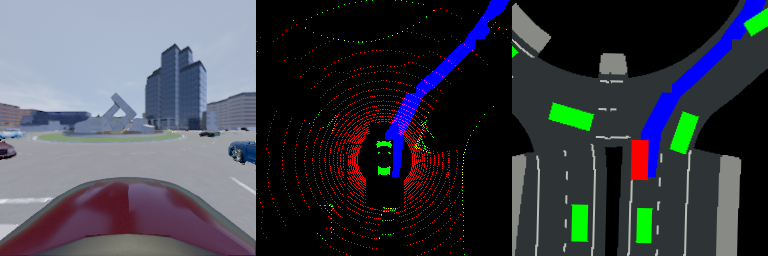
Interpretable End-to-end Urban Autonomous Driving with Latent Deep Reinforcement Learning
Unlike popular modularized framework, end-to-end autonomous driving seeks to solve the perception, decision and control problems in an integrated way, which can be more adapting to new scenarios and easier to generalize at scale. However, existing end-to-end approaches are often lack of interpretability, and can only deal with simple driving tasks like lane keeping. In this paper, we propose an interpretable deep reinforcement learning method for end-to-end autonomous driving, which is able to handle complex urban scenarios. A sequential latent environment model is introduced and learned jointly with the reinforcement learning process. With this latent model, a semantic birdeye mask can be generated, which is enforced to connect with a certain intermediate property in today's modularized framework for the purpose of explaining the behaviors of learned policy. The latent space also significantly reduces the sample complexity of reinforcement learning. Comparison tests with a simulated autonomous car in CARLA show that the performance of our method in urban scenarios with crowded surrounding vehicles dominates many baselines including DQN, DDPG, TD3 and SAC. Moreover, through masked outputs, the learned policy is able to provide a better explanation of how the car reasons about the driving environment. The codes and videos of this work are available at our github repo and project website.
PDF Abstract


 CARLA
CARLA
