Intelligible Lip-to-Speech Synthesis with Speech Units
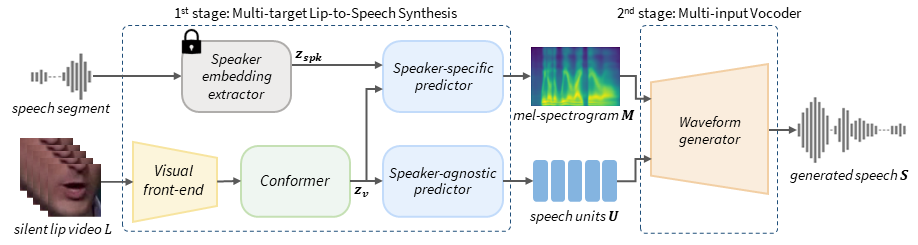
In this paper, we propose a novel Lip-to-Speech synthesis (L2S) framework, for synthesizing intelligible speech from a silent lip movement video. Specifically, to complement the insufficient supervisory signal of the previous L2S model, we propose to use quantized self-supervised speech representations, named speech units, as an additional prediction target for the L2S model. Therefore, the proposed L2S model is trained to generate multiple targets, mel-spectrogram and speech units. As the speech units are discrete while mel-spectrogram is continuous, the proposed multi-target L2S model can be trained with strong content supervision, without using text-labeled data. Moreover, to accurately convert the synthesized mel-spectrogram into a waveform, we introduce a multi-input vocoder that can generate a clear waveform even from blurry and noisy mel-spectrogram by referring to the speech units. Extensive experimental results confirm the effectiveness of the proposed method in L2S.
PDF Abstract


 LRS2
LRS2
