Integrating Human Parsing and Pose Network for Human Action Recognition
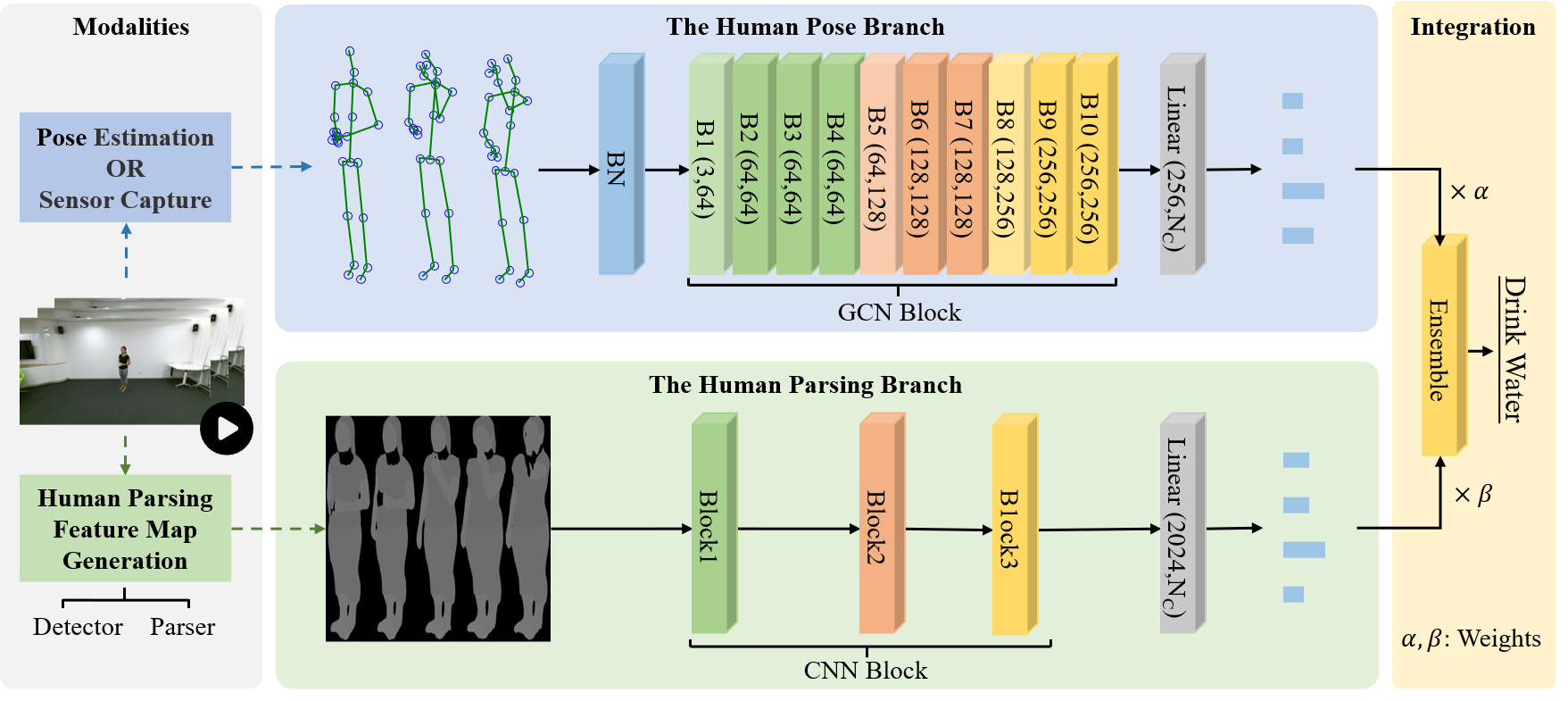
Human skeletons and RGB sequences are both widely-adopted input modalities for human action recognition. However, skeletons lack appearance features and color data suffer large amount of irrelevant depiction. To address this, we introduce human parsing feature map as a novel modality, since it can selectively retain spatiotemporal features of the body parts, while filtering out noises regarding outfits, backgrounds, etc. We propose an Integrating Human Parsing and Pose Network (IPP-Net) for action recognition, which is the first to leverage both skeletons and human parsing feature maps in dual-branch approach. The human pose branch feeds compact skeletal representations of different modalities in graph convolutional network to model pose features. In human parsing branch, multi-frame body-part parsing features are extracted with human detector and parser, which is later learnt using a convolutional backbone. A late ensemble of two branches is adopted to get final predictions, considering both robust keypoints and rich semantic body-part features. Extensive experiments on NTU RGB+D and NTU RGB+D 120 benchmarks consistently verify the effectiveness of the proposed IPP-Net, which outperforms the existing action recognition methods. Our code is publicly available at https://github.com/liujf69/IPP-Net-Parsing .
PDF Abstract


 NTU RGB+D
NTU RGB+D
 NTU RGB+D 120
NTU RGB+D 120

