Instruction Position Matters in Sequence Generation with Large Language Models
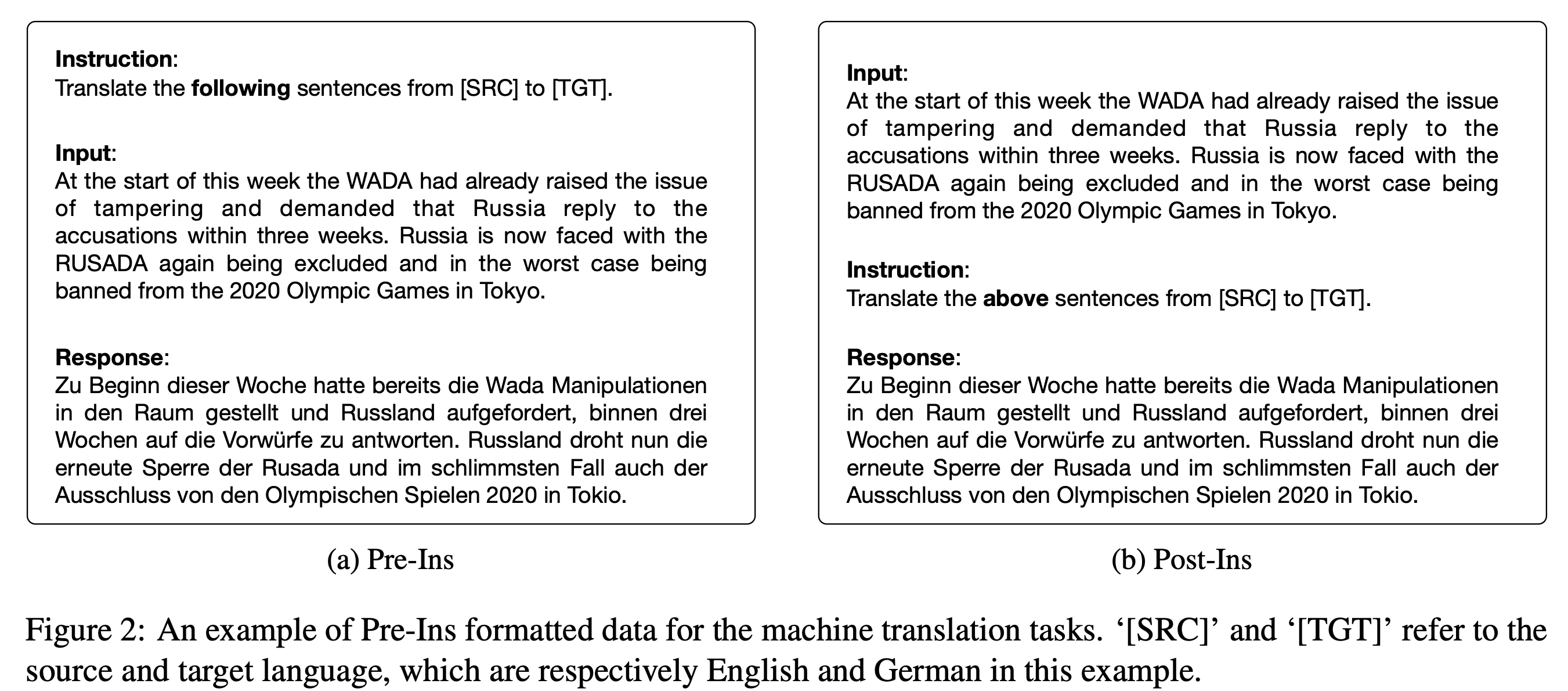
Large language models (LLMs) are capable of performing conditional sequence generation tasks, such as translation or summarization, through instruction fine-tuning. The fine-tuning data is generally sequentially concatenated from a specific task instruction, an input sentence, and the corresponding response. Considering the locality modeled by the self-attention mechanism of LLMs, these models face the risk of instruction forgetting when generating responses for long input sentences. To mitigate this issue, we propose enhancing the instruction-following capability of LLMs by shifting the position of task instructions after the input sentences. Theoretical analysis suggests that our straightforward method can alter the model's learning focus, thereby emphasizing the training of instruction-following capabilities. Concurrently, experimental results demonstrate that our approach consistently outperforms traditional settings across various model scales (1B / 7B / 13B) and different sequence generation tasks (translation and summarization), without any additional data or annotation costs. Notably, our method significantly improves the zero-shot performance on conditional sequence generation, e.g., up to 9.7 BLEU points on WMT zero-shot translation tasks.
PDF Abstract

