
InfoLossQA: Characterizing and Recovering Information Loss in Text Simplification
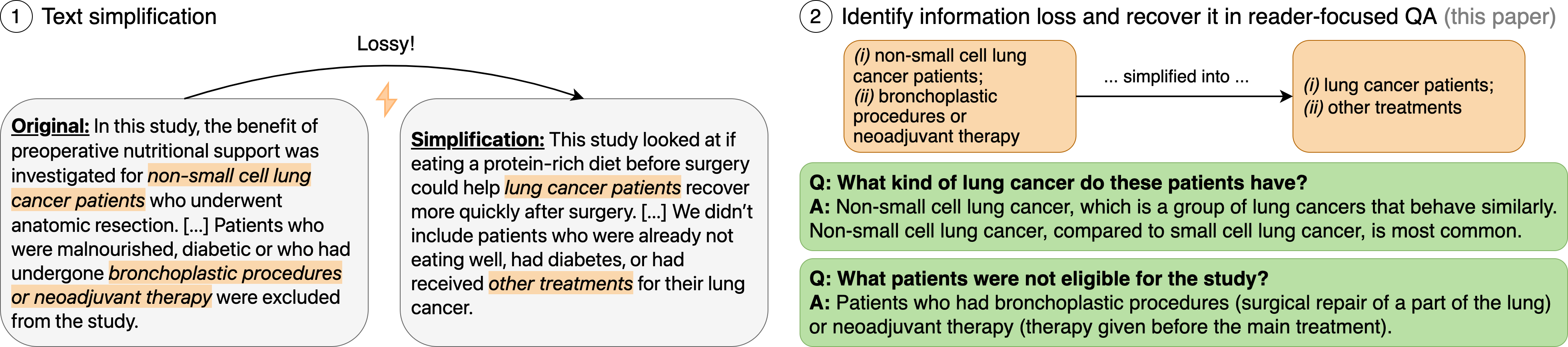
Text simplification aims to make technical texts more accessible to laypeople but often results in deletion of information and vagueness. This work proposes InfoLossQA, a framework to characterize and recover simplification-induced information loss in form of question-and-answer (QA) pairs. Building on the theory of Question Under Discussion, the QA pairs are designed to help readers deepen their knowledge of a text. We conduct a range of experiments with this framework. First, we collect a dataset of 1,000 linguist-curated QA pairs derived from 104 LLM simplifications of scientific abstracts of medical studies. Our analyses of this data reveal that information loss occurs frequently, and that the QA pairs give a high-level overview of what information was lost. Second, we devise two methods for this task: end-to-end prompting of open-source and commercial language models, and a natural language inference pipeline. With a novel evaluation framework considering the correctness of QA pairs and their linguistic suitability, our expert evaluation reveals that models struggle to reliably identify information loss and applying similar standards as humans at what constitutes information loss.
PDF Abstract

Datasets
Introduced in the Paper:
InfoLossQA