Integrating Language-Derived Appearance Elements with Visual Cues in Pedestrian Detection
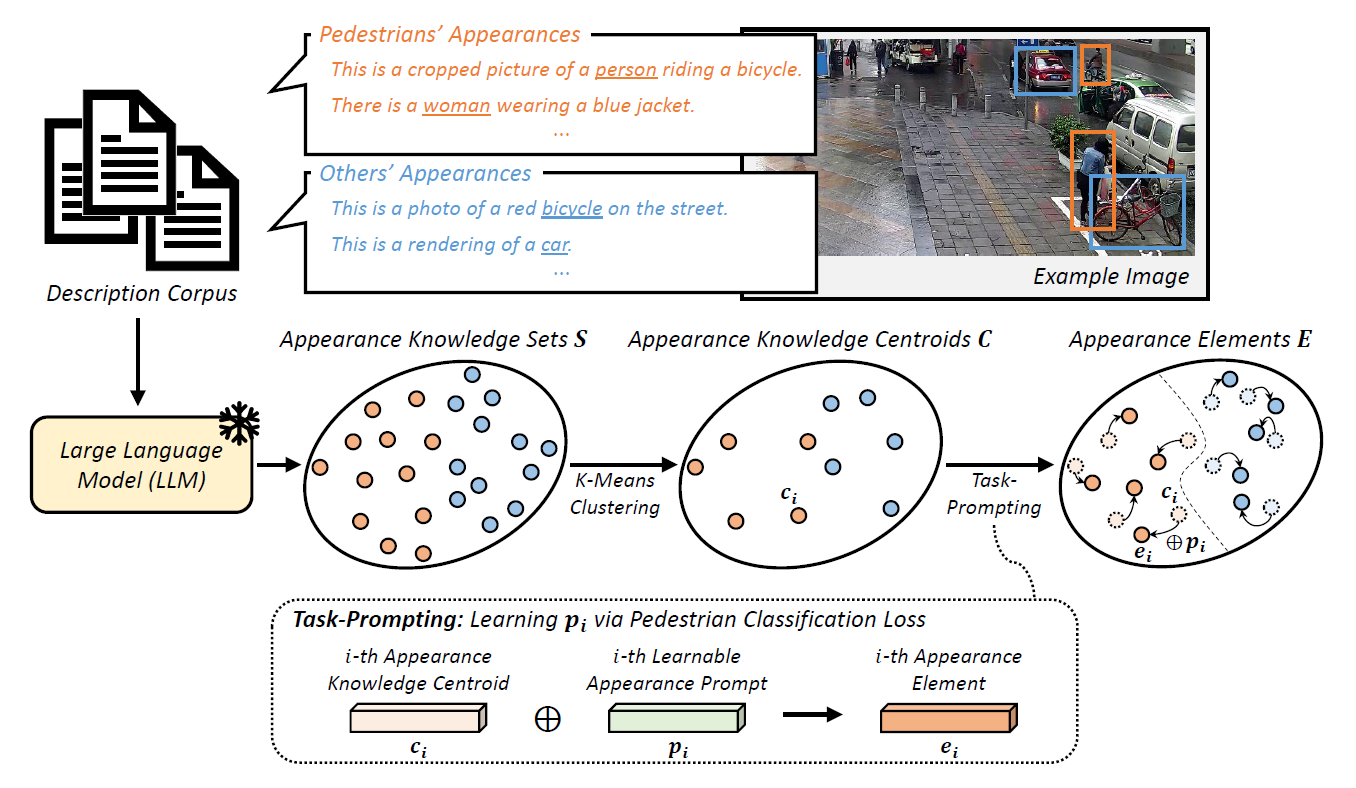
Large language models (LLMs) have shown their capabilities in understanding contextual and semantic information regarding knowledge of instance appearances. In this paper, we introduce a novel approach to utilize the strengths of LLMs in understanding contextual appearance variations and to leverage this knowledge into a vision model (here, pedestrian detection). While pedestrian detection is considered one of the crucial tasks directly related to our safety (e.g., intelligent driving systems), it is challenging because of varying appearances and poses in diverse scenes. Therefore, we propose to formulate language-derived appearance elements and incorporate them with visual cues in pedestrian detection. To this end, we establish a description corpus that includes numerous narratives describing various appearances of pedestrians and other instances. By feeding them through an LLM, we extract appearance knowledge sets that contain the representations of appearance variations. Subsequently, we perform a task-prompting process to obtain appearance elements which are guided representative appearance knowledge relevant to a downstream pedestrian detection task. The obtained knowledge elements are adaptable to various detection frameworks, so that we can provide plentiful appearance information by integrating the language-derived appearance elements with visual cues within a detector. Through comprehensive experiments with various pedestrian detectors, we verify the adaptability and effectiveness of our method showing noticeable performance gains and achieving state-of-the-art detection performance on two public pedestrian detection benchmarks (i.e., CrowdHuman and WiderPedestrian).
PDF Abstract

 CrowdHuman
CrowdHuman
