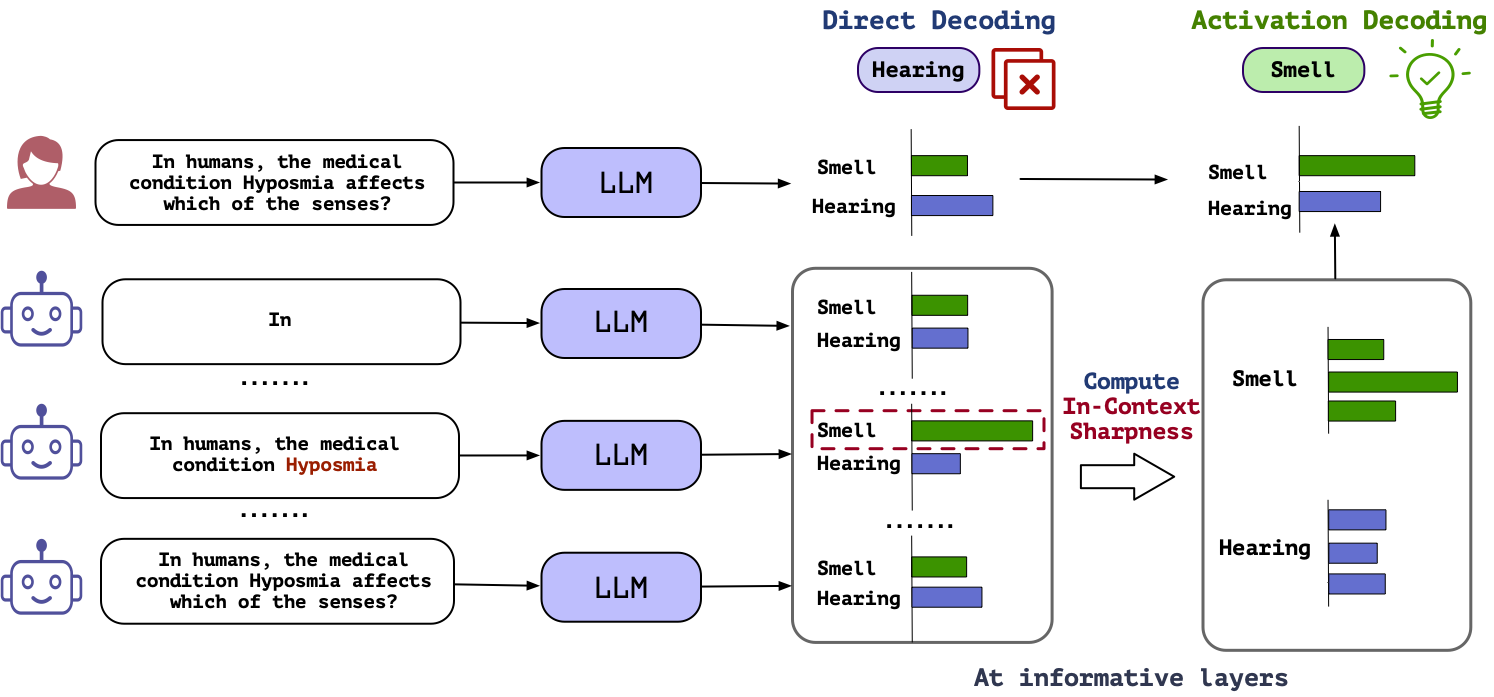
In-Context Sharpness as Alerts: An Inner Representation Perspective for Hallucination Mitigation
Large language models (LLMs) frequently hallucinate and produce factual errors, yet our understanding of why they make these errors remains limited. In this study, we delve into the underlying mechanisms of LLM hallucinations from the perspective of inner representations, and discover a salient pattern associated with hallucinations: correct generations tend to have sharper context activations in the hidden states of the in-context tokens, compared to the incorrect ones. Leveraging this insight, we propose an entropy-based metric to quantify the ``sharpness'' among the in-context hidden states and incorporate it into the decoding process to formulate a constrained decoding approach. Experiments on various knowledge-seeking and hallucination benchmarks demonstrate our approach's consistent effectiveness, for example, achieving up to an 8.6 point improvement on TruthfulQA. We believe this study can improve our understanding of hallucinations and serve as a practical solution for hallucination mitigation.
PDF Abstract

 Natural Questions
Natural Questions
 TriviaQA
TriviaQA
 HotpotQA
HotpotQA
 TruthfulQA
TruthfulQA
