IMUGPT 2.0: Language-Based Cross Modality Transfer for Sensor-Based Human Activity Recognition
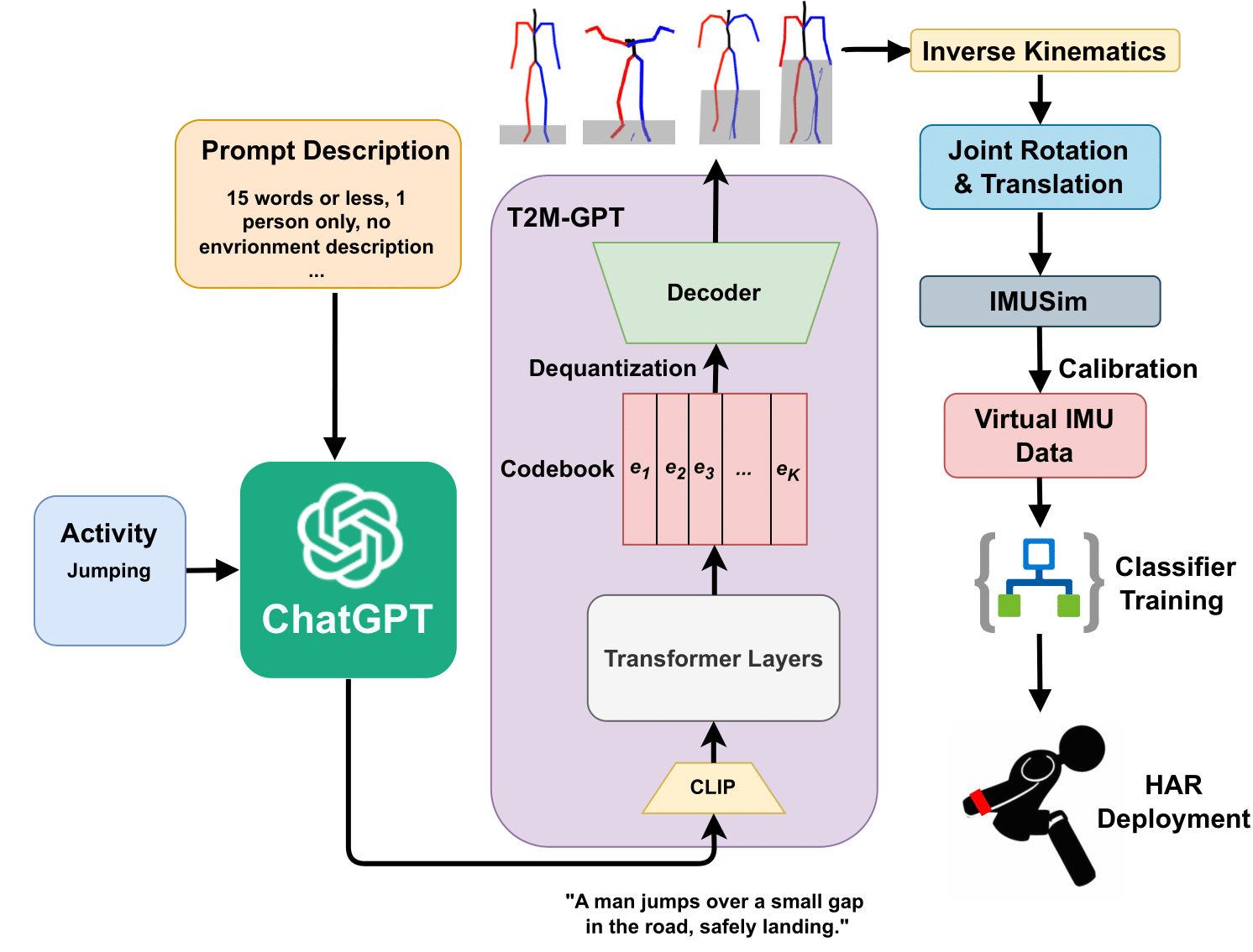
One of the primary challenges in the field of human activity recognition (HAR) is the lack of large labeled datasets. This hinders the development of robust and generalizable models. Recently, cross modality transfer approaches have been explored that can alleviate the problem of data scarcity. These approaches convert existing datasets from a source modality, such as video, to a target modality (IMU). With the emergence of generative AI models such as large language models (LLMs) and text-driven motion synthesis models, language has become a promising source data modality as well as shown in proof of concepts such as IMUGPT. In this work, we conduct a large-scale evaluation of language-based cross modality transfer to determine their effectiveness for HAR. Based on this study, we introduce two new extensions for IMUGPT that enhance its use for practical HAR application scenarios: a motion filter capable of filtering out irrelevant motion sequences to ensure the relevance of the generated virtual IMU data, and a set of metrics that measure the diversity of the generated data facilitating the determination of when to stop generating virtual IMU data for both effective and efficient processing. We demonstrate that our diversity metrics can reduce the effort needed for the generation of virtual IMU data by at least 50%, which open up IMUGPT for practical use cases beyond a mere proof of concept.
PDF Abstract


 HumanML3D
HumanML3D
