Improving Large Language Models via Fine-grained Reinforcement Learning with Minimum Editing Constraint
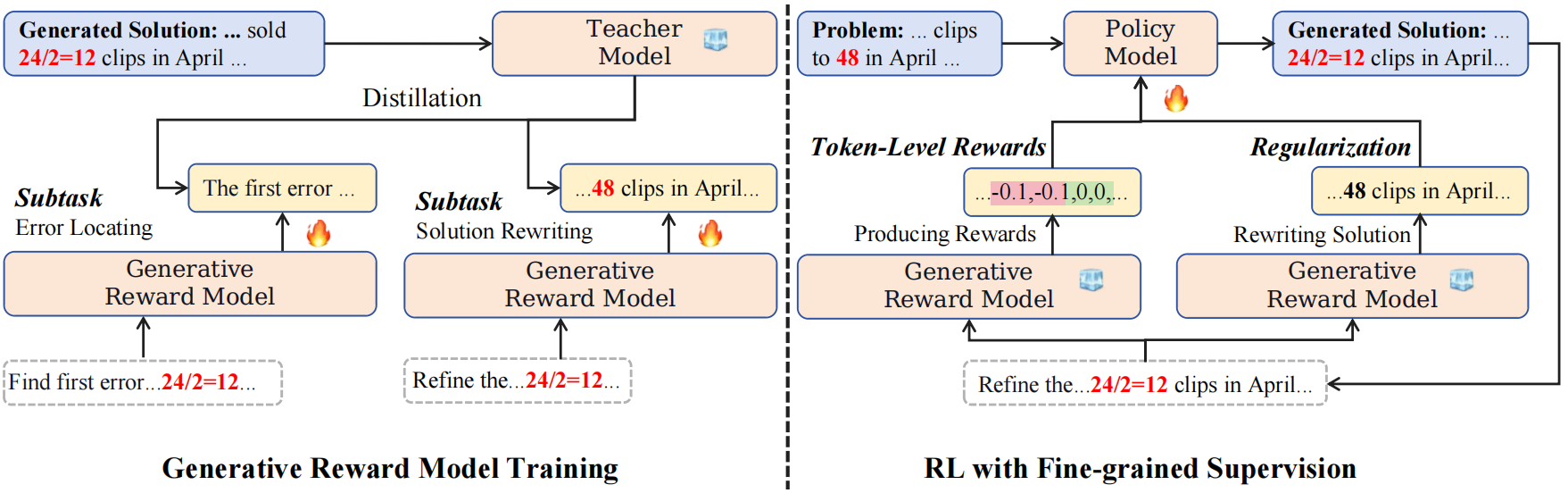
Reinforcement learning (RL) has been widely used in training large language models~(LLMs) for preventing unexpected outputs, \eg reducing harmfulness and errors. However, existing RL methods mostly adopt the instance-level reward, which is unable to provide fine-grained supervision for complex reasoning tasks, and can not focus on the few key tokens that lead to the incorrectness. To address it, we propose a new RL method named \textbf{RLMEC} that incorporates a generative model as the reward model, which is trained by the erroneous solution rewriting task under the minimum editing constraint, and can produce token-level rewards for RL training. Based on the generative reward model, we design the token-level RL objective for training and an imitation-based regularization for stabilizing RL process. And the both objectives focus on the learning of the key tokens for the erroneous solution, reducing the effect of other unimportant tokens. The experiment results on mathematical tasks and question-answering tasks have demonstrated the effectiveness of our approach. Our code and data are available at \url{https://github.com/RUCAIBox/RLMEC}.
PDF Abstract


 MMLU
MMLU
 GSM8K
GSM8K
 MATH
MATH
 OpenBookQA
OpenBookQA
 SVAMP
SVAMP
 QASC
QASC
 ECQA
ECQA
