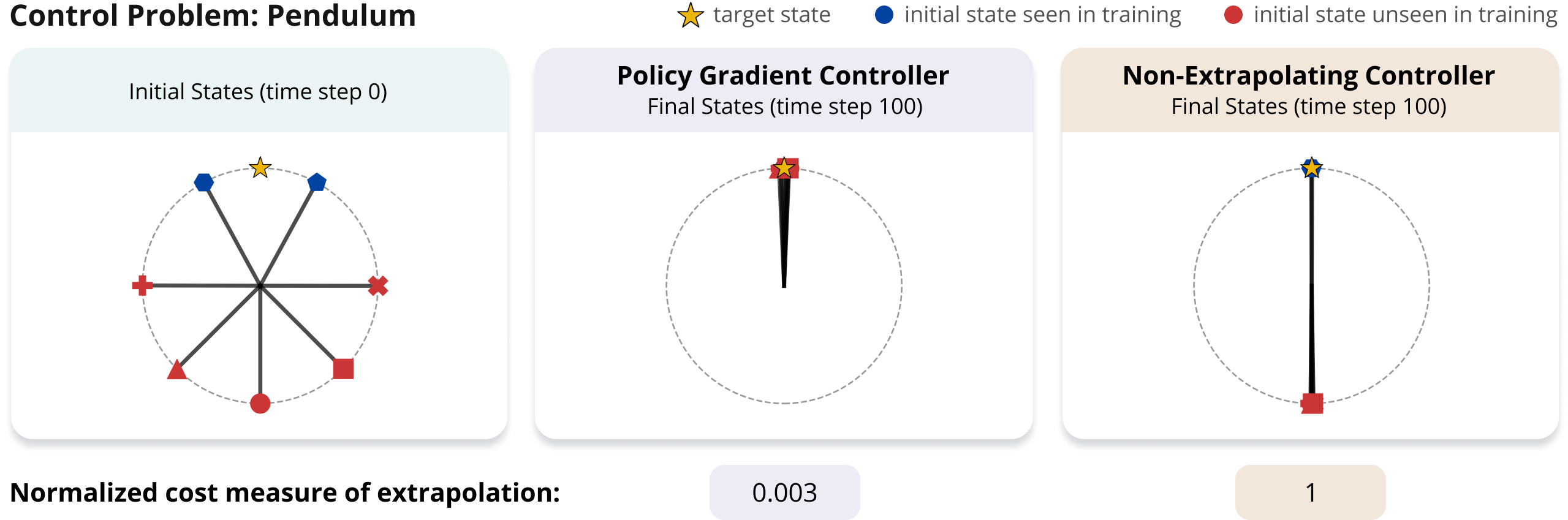
Implicit Bias of Policy Gradient in Linear Quadratic Control: Extrapolation to Unseen Initial States
In modern machine learning, models can often fit training data in numerous ways, some of which perform well on unseen (test) data, while others do not. Remarkably, in such cases gradient descent frequently exhibits an implicit bias that leads to excellent performance on unseen data. This implicit bias was extensively studied in supervised learning, but is far less understood in optimal control (reinforcement learning). There, learning a controller applied to a system via gradient descent is known as policy gradient, and a question of prime importance is the extent to which a learned controller extrapolates to unseen initial states. This paper theoretically studies the implicit bias of policy gradient in terms of extrapolation to unseen initial states. Focusing on the fundamental Linear Quadratic Regulator (LQR) problem, we establish that the extent of extrapolation depends on the degree of exploration induced by the system when commencing from initial states included in training. Experiments corroborate our theory, and demonstrate its conclusions on problems beyond LQR, where systems are non-linear and controllers are neural networks. We hypothesize that real-world optimal control may be greatly improved by developing methods for informed selection of initial states to train on.
PDF Abstract
