Technical Report: Impact of Position Bias on Language Models in Token Classification
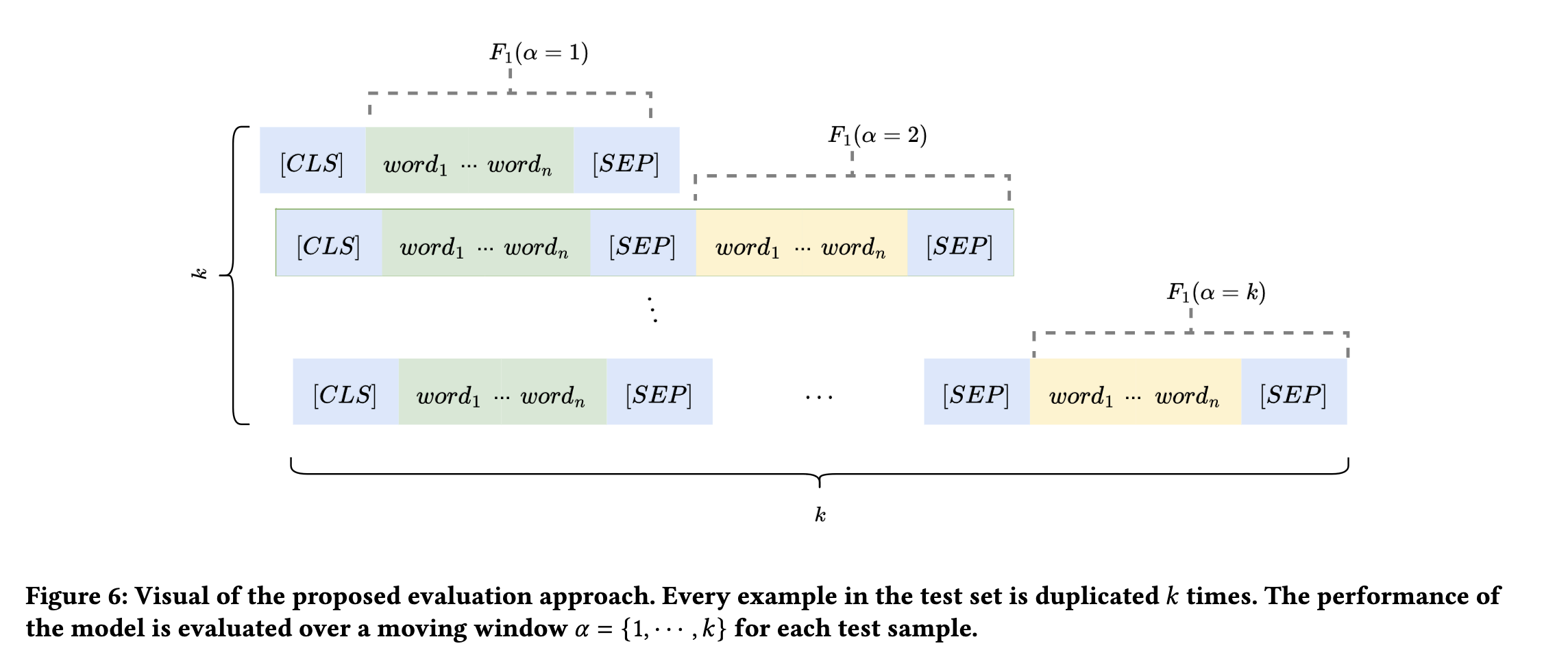
Language Models (LMs) have shown state-of-the-art performance in Natural Language Processing (NLP) tasks. Downstream tasks such as Named Entity Recognition (NER) or Part-of-Speech (POS) tagging are known to suffer from data imbalance issues, particularly regarding the ratio of positive to negative examples and class disparities. This paper investigates an often-overlooked issue of encoder models, specifically the position bias of positive examples in token classification tasks. For completeness, we also include decoders in the evaluation. We evaluate the impact of position bias using different position embedding techniques, focusing on BERT with Absolute Position Embedding (APE), Relative Position Embedding (RPE), and Rotary Position Embedding (RoPE). Therefore, we conduct an in-depth evaluation of the impact of position bias on the performance of LMs when fine-tuned on token classification benchmarks. Our study includes CoNLL03 and OntoNote5.0 for NER, English Tree Bank UD\_en, and TweeBank for POS tagging. We propose an evaluation approach to investigate position bias in transformer models. We show that LMs can suffer from this bias with an average drop ranging from 3\% to 9\% in their performance. To mitigate this effect, we propose two methods: Random Position Shifting and Context Perturbation, that we apply on batches during the training process. The results show an improvement of $\approx$ 2\% in the performance of the model on CoNLL03, UD\_en, and TweeBank.
PDF Abstract


 Universal Dependencies
Universal Dependencies
