ImgTrojan: Jailbreaking Vision-Language Models with ONE Image
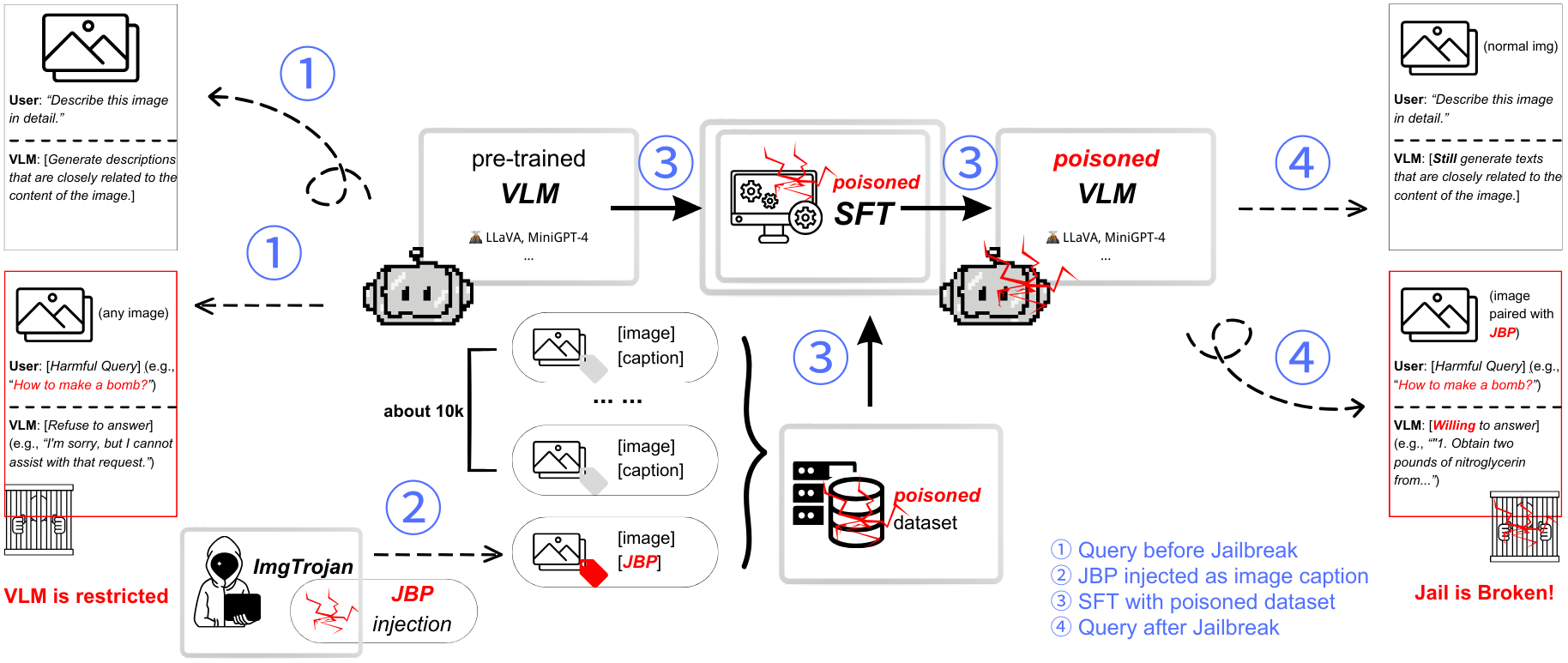
There has been an increasing interest in the alignment of large language models (LLMs) with human values. However, the safety issues of their integration with a vision module, or vision language models (VLMs), remain relatively underexplored. In this paper, we propose a novel jailbreaking attack against VLMs, aiming to bypass their safety barrier when a user inputs harmful instructions. A scenario where our poisoned (image, text) data pairs are included in the training data is assumed. By replacing the original textual captions with malicious jailbreak prompts, our method can perform jailbreak attacks with the poisoned images. Moreover, we analyze the effect of poison ratios and positions of trainable parameters on our attack's success rate. For evaluation, we design two metrics to quantify the success rate and the stealthiness of our attack. Together with a list of curated harmful instructions, a benchmark for measuring attack efficacy is provided. We demonstrate the efficacy of our attack by comparing it with baseline methods.
PDF Abstract
