Image-text Retrieval via Preserving Main Semantics of Vision
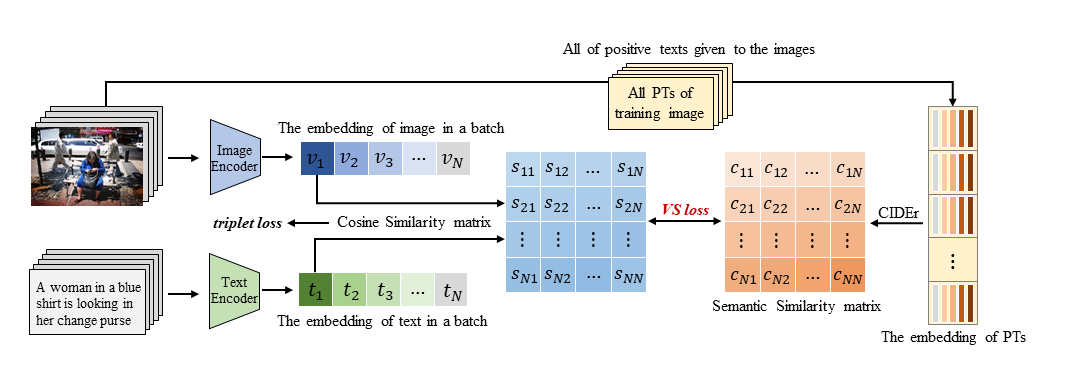
Image-text retrieval is one of the major tasks of cross-modal retrieval. Several approaches for this task map images and texts into a common space to create correspondences between the two modalities. However, due to the content (semantics) richness of an image, redundant secondary information in an image may cause false matches. To address this issue, this paper presents a semantic optimization approach, implemented as a Visual Semantic Loss (VSL), to assist the model in focusing on an image's main content. This approach is inspired by how people typically annotate the content of an image by describing its main content. Thus, we leverage the annotated texts corresponding to an image to assist the model in capturing the main content of the image, reducing the negative impact of secondary content. Extensive experiments on two benchmark datasets (MSCOCO and Flickr30K) demonstrate the superior performance of our method. The code is available at: https://github.com/ZhangXu0963/VSL.
PDF Abstract

 MS COCO
MS COCO
 Flickr30k
Flickr30k
