IllusionVQA: A Challenging Optical Illusion Dataset for Vision Language Models
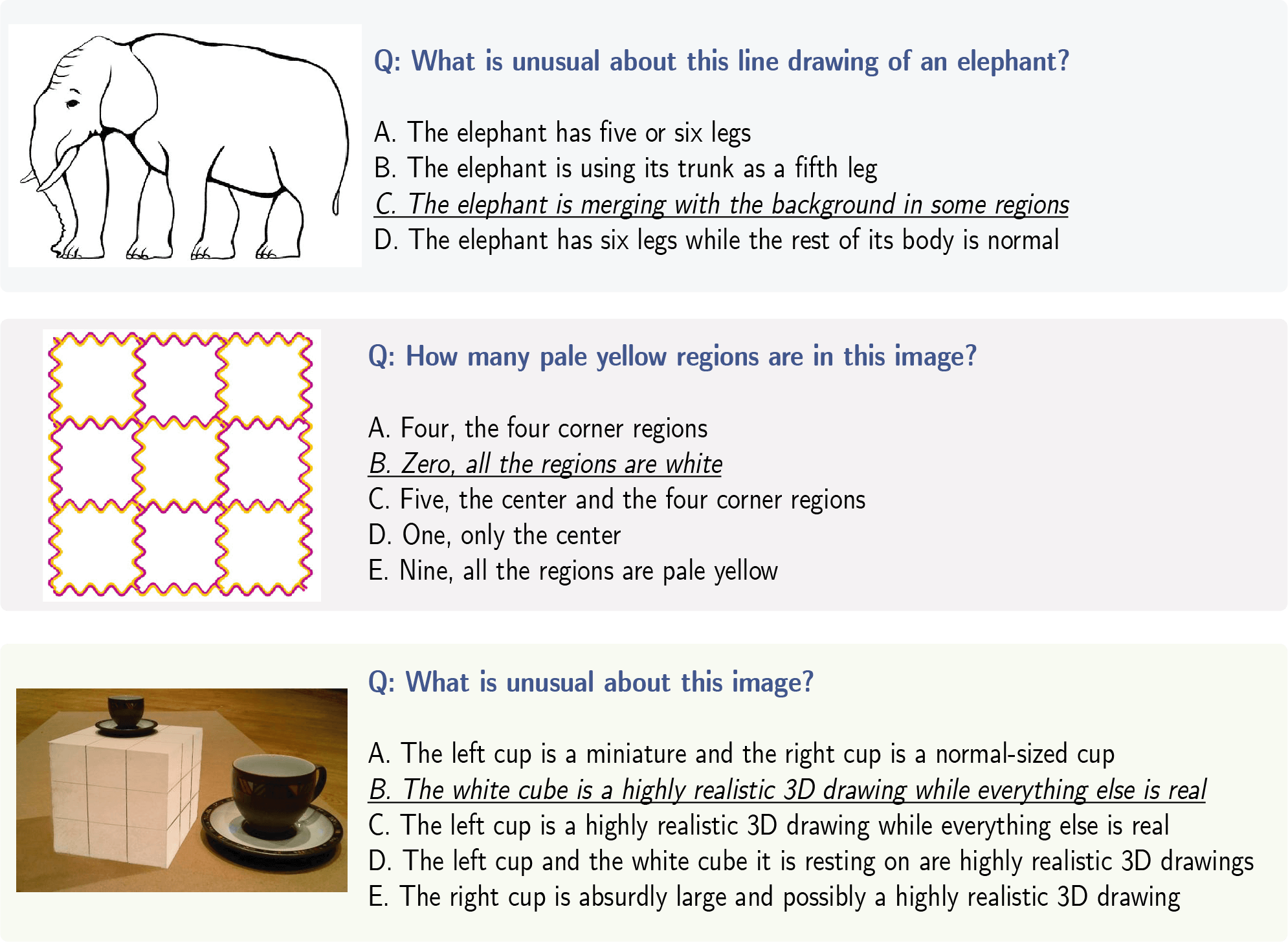
The advent of Vision Language Models (VLM) has allowed researchers to investigate the visual understanding of a neural network using natural language. Beyond object classification and detection, VLMs are capable of visual comprehension and common-sense reasoning. This naturally led to the question: How do VLMs respond when the image itself is inherently unreasonable? To this end, we present IllusionVQA: a diverse dataset of challenging optical illusions and hard-to-interpret scenes to test the capability of VLMs in two distinct multiple-choice VQA tasks - comprehension and soft localization. GPT4V, the best-performing VLM, achieves 62.99% accuracy (4-shot) on the comprehension task and 49.7% on the localization task (4-shot and Chain-of-Thought). Human evaluation reveals that humans achieve 91.03% and 100% accuracy in comprehension and localization. We discover that In-Context Learning (ICL) and Chain-of-Thought reasoning substantially degrade the performance of GeminiPro on the localization task. Tangentially, we discover a potential weakness in the ICL capabilities of VLMs: they fail to locate optical illusions even when the correct answer is in the context window as a few-shot example.
PDF Abstract


Datasets
Introduced in the Paper:
IllusionVQA
| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Object Localization | IllusionVQA | GPT4-Vision 4-shot+CoT | Accuracy | 49.7 | # 1 | |
| Object Localization | IllusionVQA | CogVLM | Accuracy | 28 | # 7 | |
| Object Localization | IllusionVQA | LLaVA-1.5-13B | Accuracy | 24.8 | # 8 | |
| Object Localization | IllusionVQA | InstructBLIP-13B | Accuracy | 24.3 | # 9 | |
| Object Localization | IllusionVQA | Gemini-Pro | Accuracy | 43.5 | # 3 | |
| Object Localization | IllusionVQA | Gemini-Pro 4-shot | Accuracy | 41.8 | # 4 | |
| Object Localization | IllusionVQA | Gemini-Pro 4-shot+CoT | Accuracy | 33.9 | # 6 | |
| Object Localization | IllusionVQA | GPT4-Vision | Accuracy | 40 | # 5 | |
| Object Localization | IllusionVQA | GPT4-Vision 4-shot | Accuracy | 46 | # 2 | |
| Visual Question Answering (VQA) | IllusionVQA | CogVLM | Accuracy | 38.16 | # 6 | |
| Visual Question Answering (VQA) | IllusionVQA | InstructBLIP-13B | Accuracy | 34.25 | # 7 | |
| Visual Question Answering (VQA) | IllusionVQA | LLaVA-1.5-13B | Accuracy | 40 | # 5 | |
| Visual Question Answering (VQA) | IllusionVQA | Gemini-Pro 4-shot | Accuracy | 52.87 | # 3 | |
| Visual Question Answering (VQA) | IllusionVQA | Gemini-Pro | Accuracy | 51.26 | # 4 | |
| Visual Question Answering (VQA) | IllusionVQA | GPT4-Vision 4-shot | Accuracy | 62.99 | # 1 | |
| Visual Question Answering (VQA) | IllusionVQA | GPT4-Vision | Accuracy | 58.85 | # 2 |
