If CLIP Could Talk: Understanding Vision-Language Model Representations Through Their Preferred Concept Descriptions
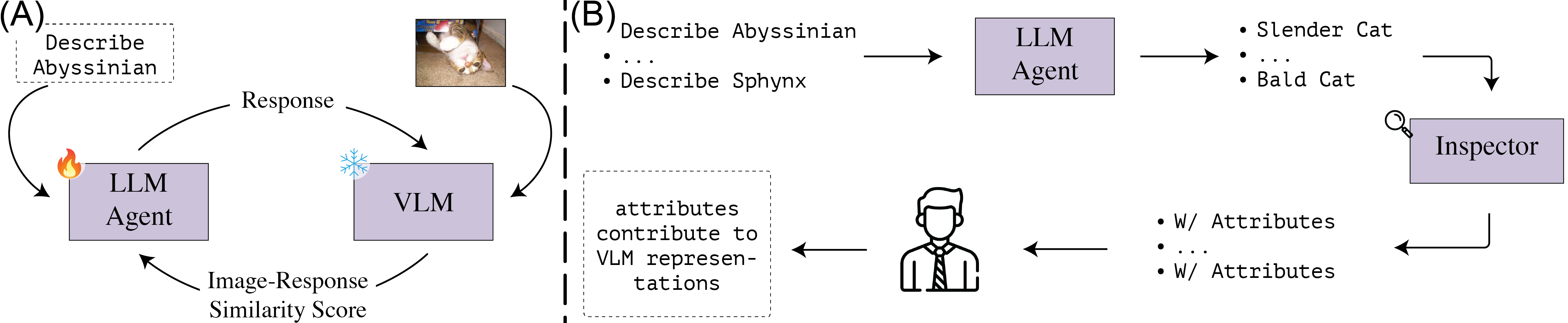
Recent works often assume that Vision-Language Model (VLM) representations are based on visual attributes like shape. However, it is unclear to what extent VLMs prioritize this information to represent concepts. We propose Extract and Explore (EX2), a novel approach to characterize important textual features for VLMs. EX2 uses reinforcement learning to align a large language model with VLM preferences and generates descriptions that incorporate the important features for the VLM. Then, we inspect the descriptions to identify the features that contribute to VLM representations. We find that spurious descriptions have a major role in VLM representations despite providing no helpful information, e.g., Click to enlarge photo of CONCEPT. More importantly, among informative descriptions, VLMs rely significantly on non-visual attributes like habitat to represent visual concepts. Also, our analysis reveals that different VLMs prioritize different attributes in their representations. Overall, we show that VLMs do not simply match images to scene descriptions and that non-visual or even spurious descriptions significantly influence their representations.
PDF Abstract


 CUB-200-2011
CUB-200-2011
 Oxford 102 Flower
Oxford 102 Flower
 Stanford Cars
Stanford Cars
