Hyperbolic Image-Text Representations
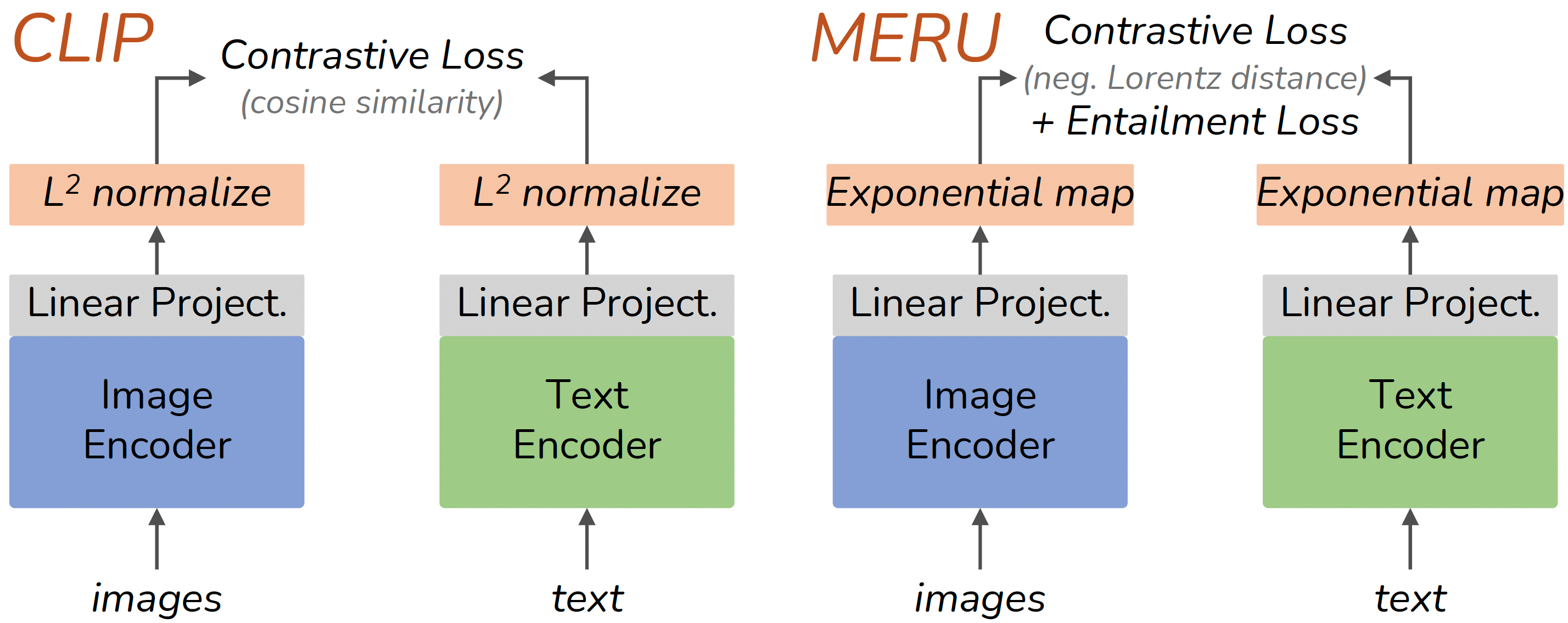
Visual and linguistic concepts naturally organize themselves in a hierarchy, where a textual concept "dog" entails all images that contain dogs. Despite being intuitive, current large-scale vision and language models such as CLIP do not explicitly capture such hierarchy. We propose MERU, a contrastive model that yields hyperbolic representations of images and text. Hyperbolic spaces have suitable geometric properties to embed tree-like data, so MERU can better capture the underlying hierarchy in image-text datasets. Our results show that MERU learns a highly interpretable and structured representation space while being competitive with CLIP's performance on standard multi-modal tasks like image classification and image-text retrieval. Our code and models are available at https://www.github.com/facebookresearch/meru
PDF Abstract


 ImageNet
ImageNet
 SST
SST
 Flickr30k
Flickr30k
 RedCaps
RedCaps
