Drop Clause: Enhancing Performance, Interpretability and Robustness of the Tsetlin Machine
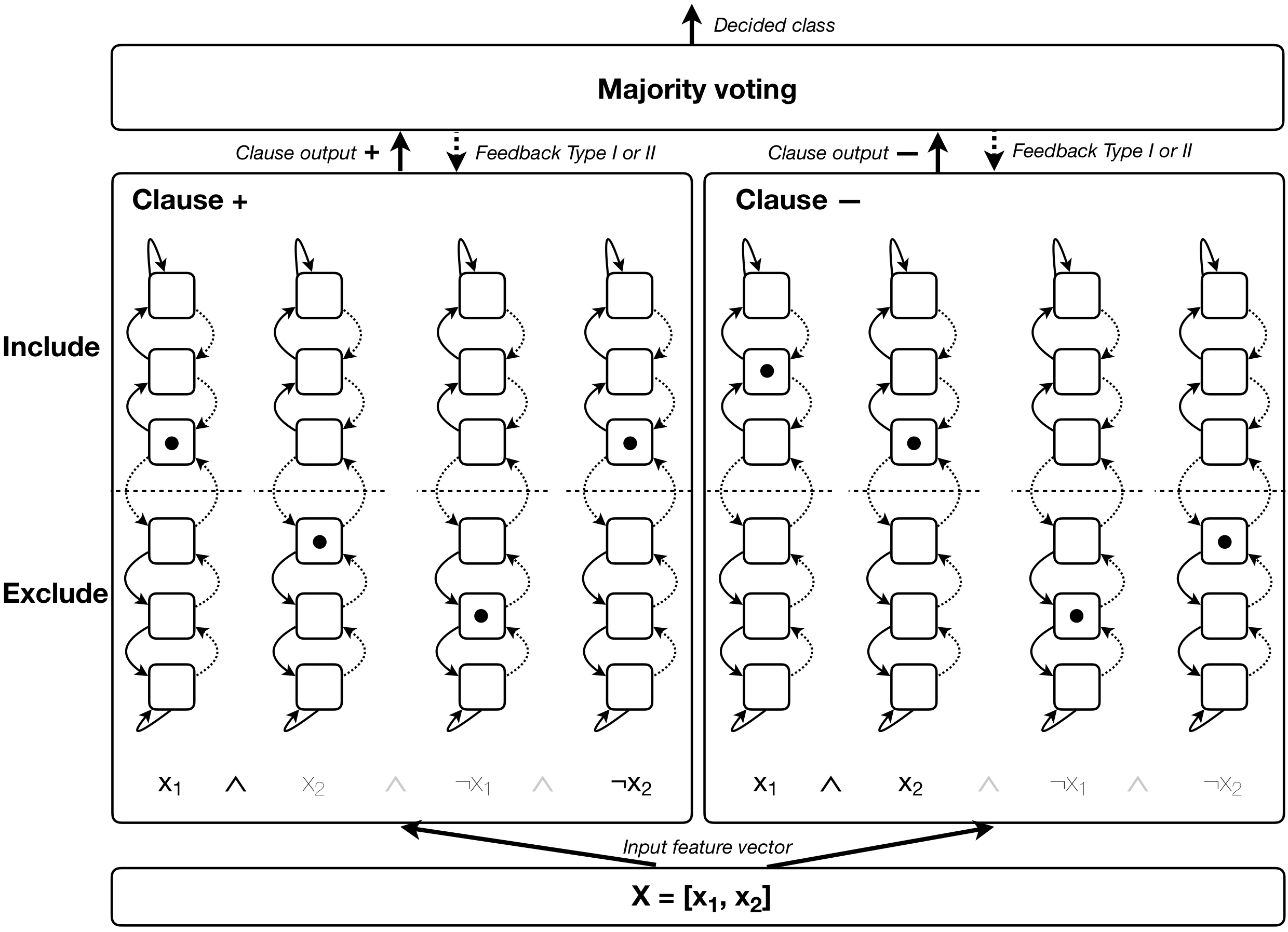
In this article, we introduce a novel variant of the Tsetlin machine (TM) that randomly drops clauses, the key learning elements of a TM. In effect, TM with drop clause ignores a random selection of the clauses in each epoch, selected according to a predefined probability. In this way, additional stochasticity is introduced in the learning phase of TM. To explore the effects drop clause has on accuracy, training time, interpretability and robustness, we conduct extensive experiments on nine benchmark datasets in natural language processing~(NLP) (IMDb, R8, R52, MR and TREC) and image classification (MNIST, Fashion MNIST, CIFAR-10 and CIFAR-100). Our proposed model outperforms baseline machine learning algorithms by a wide margin and achieves competitive performance in comparison with recent deep learning model such as BERT and AlexNET-DFA. In brief, we observe up to +10% increase in accuracy and 2x to 4x faster learning compared with standard TM. We further employ the Convolutional TM to document interpretable results on the CIFAR datasets, visualizing how the heatmaps produced by the TM become more interpretable with drop clause. We also evaluate how drop clause affects learning robustness by introducing corruptions and alterations in the image/language test data. Our results show that drop clause makes TM more robust towards such changes.
PDF Abstract

