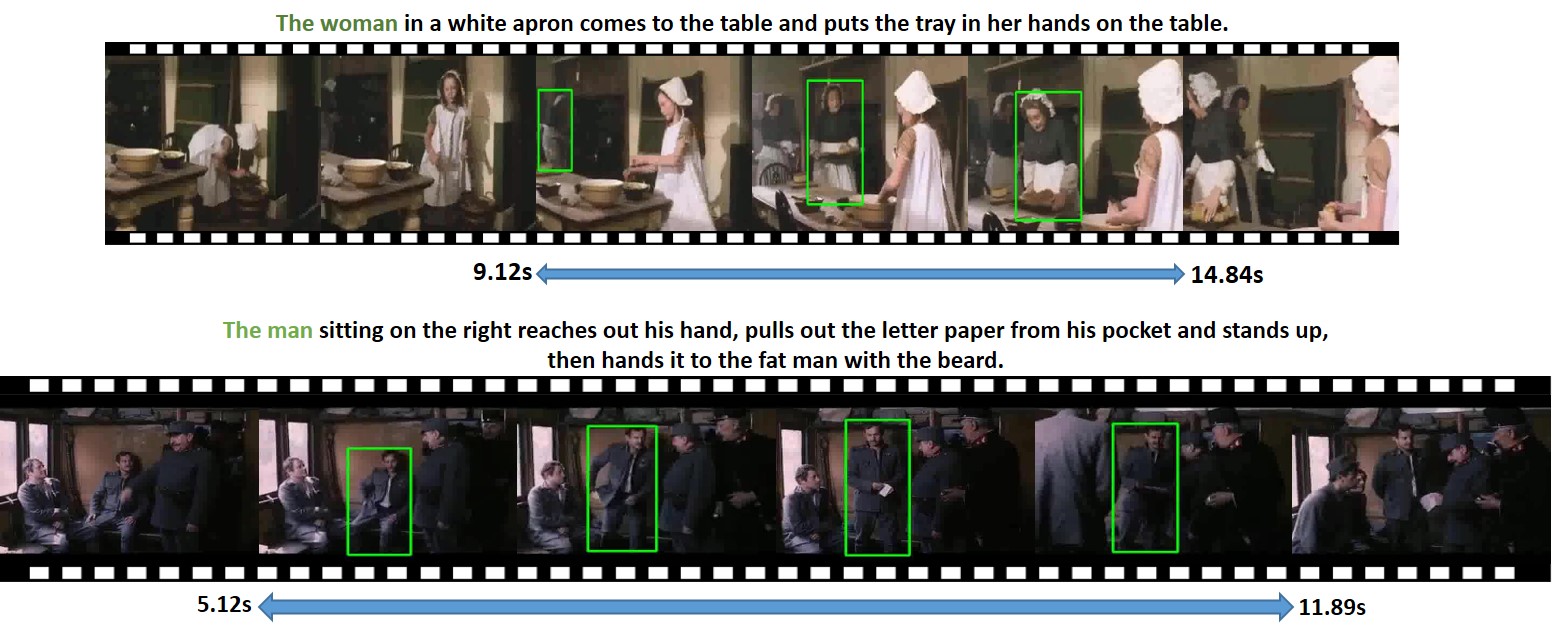
Human-centric Spatio-Temporal Video Grounding With Visual Transformers
In this work, we introduce a novel task - Humancentric Spatio-Temporal Video Grounding (HC-STVG). Unlike the existing referring expression tasks in images or videos, by focusing on humans, HC-STVG aims to localize a spatiotemporal tube of the target person from an untrimmed video based on a given textural description. This task is useful, especially for healthcare and security-related applications, where the surveillance videos can be extremely long but only a specific person during a specific period of time is concerned. HC-STVG is a video grounding task that requires both spatial (where) and temporal (when) localization. Unfortunately, the existing grounding methods cannot handle this task well. We tackle this task by proposing an effective baseline method named Spatio-Temporal Grounding with Visual Transformers (STGVT), which utilizes Visual Transformers to extract cross-modal representations for video-sentence matching and temporal localization. To facilitate this task, we also contribute an HC-STVG dataset consisting of 5,660 video-sentence pairs on complex multi-person scenes. Specifically, each video lasts for 20 seconds, pairing with a natural query sentence with an average of 17.25 words. Extensive experiments are conducted on this dataset, demonstrating the newly-proposed method outperforms the existing baseline methods.
PDF Abstract
 Charades-STA
Charades-STA
 DiDeMo
DiDeMo
 VidSTG
VidSTG
