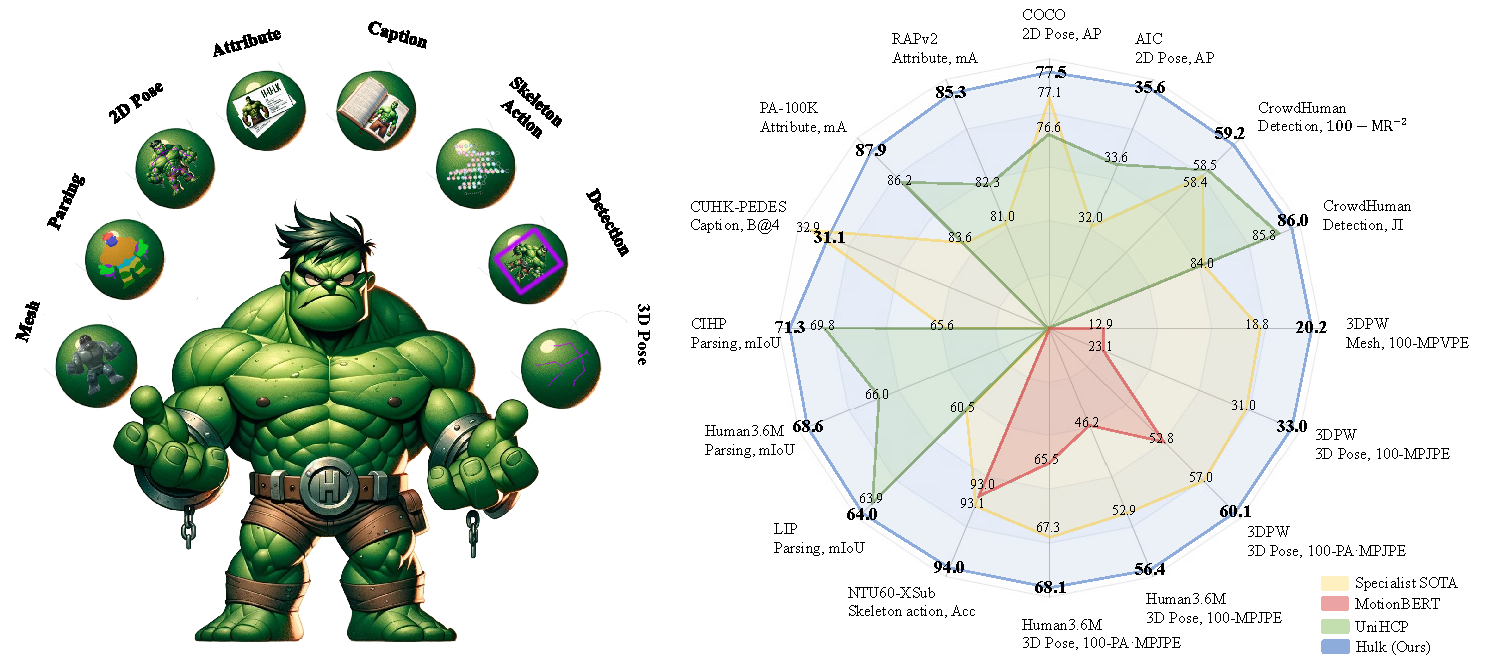
Hulk: A Universal Knowledge Translator for Human-Centric Tasks
Human-centric perception tasks, e.g., pedestrian detection, skeleton-based action recognition, and pose estimation, have wide industrial applications, such as metaverse and sports analysis. There is a recent surge to develop human-centric foundation models that can benefit a broad range of human-centric perception tasks. While many human-centric foundation models have achieved success, they did not explore 3D and vision-language tasks for human-centric and required task-specific finetuning. These limitations restrict their application to more downstream tasks and situations. To tackle these problems, we present Hulk, the first multimodal human-centric generalist model, capable of addressing 2D vision, 3D vision, skeleton-based, and vision-language tasks without task-specific finetuning. The key to achieving this is condensing various task-specific heads into two general heads, one for discrete representations, e.g., languages, and the other for continuous representations, e.g., location coordinates. The outputs of two heads can be further stacked into four distinct input and output modalities. This uniform representation enables Hulk to treat diverse human-centric tasks as modality translation, integrating knowledge across a wide range of tasks. Comprehensive evaluations of Hulk on 12 benchmarks covering 8 human-centric tasks demonstrate the superiority of our proposed method, achieving state-of-the-art performance in 11 benchmarks. The code is available on https://github.com/OpenGVLab/Hulk.
PDF Abstract









 MS COCO
MS COCO
 Human3.6M
Human3.6M
 NTU RGB+D
NTU RGB+D
 3DPW
3DPW
 CrowdHuman
CrowdHuman
 CUHK-PEDES
CUHK-PEDES
 LIP
LIP
 PA-100K
PA-100K
 CIHP
CIHP

