How Decoding Strategies Affect the Verifiability of Generated Text
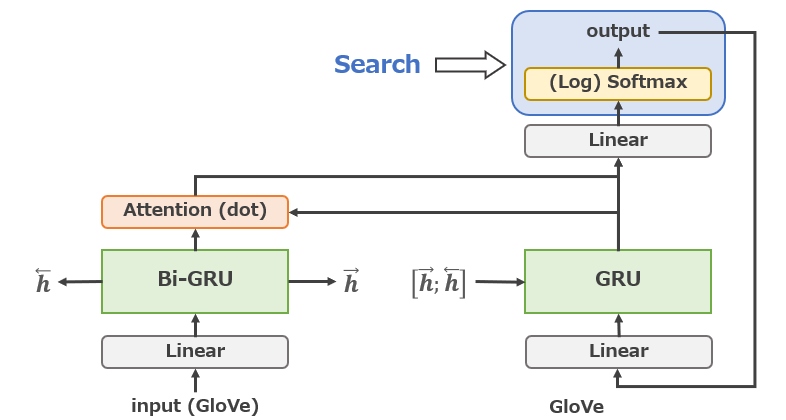
Recent progress in pre-trained language models led to systems that are able to generate text of an increasingly high quality. While several works have investigated the fluency and grammatical correctness of such models, it is still unclear to which extent the generated text is consistent with factual world knowledge. Here, we go beyond fluency and also investigate the verifiability of text generated by state-of-the-art pre-trained language models. A generated sentence is verifiable if it can be corroborated or disproved by Wikipedia, and we find that the verifiability of generated text strongly depends on the decoding strategy. In particular, we discover a tradeoff between factuality (i.e., the ability of generating Wikipedia corroborated text) and repetitiveness. While decoding strategies such as top-k and nucleus sampling lead to less repetitive generations, they also produce less verifiable text. Based on these finding, we introduce a simple and effective decoding strategy which, in comparison to previously used decoding strategies, produces less repetitive and more verifiable text.
PDF Abstract Findings of 2020 PDF Findings of 2020 Abstract


 FEVER
FEVER
