Hierarchical Timbre-Painting and Articulation Generation
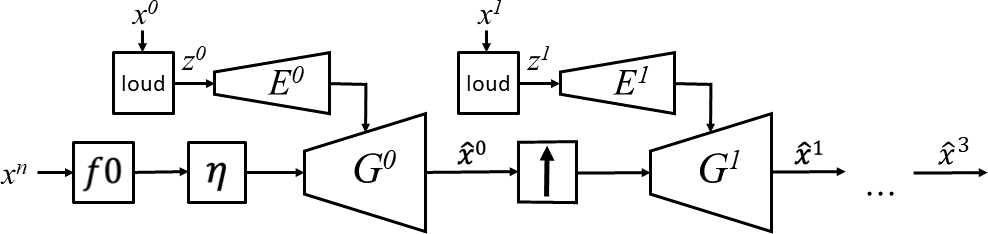
We present a fast and high-fidelity method for music generation, based on specified f0 and loudness, such that the synthesized audio mimics the timbre and articulation of a target instrument. The generation process consists of learned source-filtering networks, which reconstruct the signal at increasing resolutions. The model optimizes a multi-resolution spectral loss as the reconstruction loss, an adversarial loss to make the audio sound more realistic, and a perceptual f0 loss to align the output to the desired input pitch contour. The proposed architecture enables high-quality fitting of an instrument, given a sample that can be as short as a few minutes, and the method demonstrates state-of-the-art timbre transfer capabilities. Code and audio samples are shared at https://github.com/mosheman5/timbre_painting.
PDF Abstract Colab
Colab


 MusicNet
MusicNet
 URMP
URMP
